

서 론
다층신경망을 이용한 건물 부하 예측 모델
다층신경망 개요
다층신경망 주요 입력 매개변수(Parameter) 설정
신경망 학습을 위한 데이터 생성
데이터 전처리 방법과 예측 성능 평가
데이터 전처리 방법
예측 모델의 성능 평가 방법
결과분석
데이터 전처리 과정에 따른 예측 결과
CvRMSE 지표에 의한 예측 성능 비교
MBE 지표에 의한 예측 성능 비교
종합 분석
결 론
서 론
최근 에너지 관련 통계의 보고에 따르면(IEA, 2019) 전체 에너지 사용량 중 최종적으로 사용되는 에너지의 30% 이상, 온실가스배출에서는 3/4 이상을 건물 부문이 차지하는 것으로 나타났다. 건물에서 거주자의 쾌적한 환경을 제공하기 위해 건물 에너지의 50% 이상은 공조 설비의 운전에 소비되고 있기 때문에(DOE, 2015) 건물의 운전과 운영단계에서 효율적인 에너지 사용과 관리가 이루어져야 하며(Seong and Hong, 2021) 이를 위해 정확한 건물의 에너지 수요와 부하 예측이 필요하다. 본 연구에서는 기계학습 방법 중 인공신경망(ANN, Artificial Neural Networks) 중 하나인 다층신경망(Multilayer Neural Network)을 이용하여 건물 부하 예측 시에 건물의 부하를 정확하고 효과적으로 예측하기 위해서 데이터 전처리 과정이 예측 모델의 성능에 미치는 영향을 비교하고 평가하였다.
데이터의 전처리 과정은 데이터 기반 모델의 입력 품질을 향상하는 과정으로 신경망 모델 성능에 큰 영향을 미치는 것으로 알려져 있다(Humphrey et al., 2016). 데이터를 기반으로 하는 건물의 부하 예측(Oprea and Bâra, 2019), 건물 에너지 예측 모델의 성능향상(Amasyali and El-Gohary, 2018), 군집화(Clustering)에 따른 에너지 사용량의 분석(Sung and Cho, 2019), 데이터 기반의 분류모델(Lee et al., 2020) 등에도 기본적으로 활용된다. 이처럼 데이터 전처리의 중요성을 고려하여 데이터의 전처리 과정은 모델의 개발이나 모델의 성능향상을 위해 많은 연구에 활용되고 있으나 데이터의 전처리 과정이 실제 모델의 예측 성능에 미치는 영향에 대한 분석은 부족한 실정이다. 따라서 본 연구에서는 신경망 기반 예측 모델에서 데이터 전처리 방법과 과정이 예측 성능에 미치는 영향을 비교 분석하였으며 연구의 결과는 건물 부하 예측 모델의 예측 성능향상에 활용될 수 있을 것으로 기대한다.
다층신경망을 이용한 건물 부하 예측 모델
다층신경망 개요
다층신경망은 입력층(input layer), 은닉층(hidden layer), 출력층(output layer)의 여러 층으로 구성된 신경망 모델을 말하며, 은닉층의 개수에 따라 얕은(Shallow) 신경망과 심층(Deep) 신경망으로 나뉜다(Kim and Gofman, 2018). 본 연구에서는 Matlab R2020a (MathWorks Korea, 2020)의 Neural Networks Toolbox에 포함되어있는 신경망 모델을 사용하여 다층신경망을 구성하고 업무용 건물의 냉방 부하를 예측하였다. 본 연구에 사용된 다층신경망의 구조는 선행된 연구(Kim et al., 2021)의 유형과 같으며 입출력을 포함한 다층신경망의 구조를 도식화하면 Figure 1과 같다.
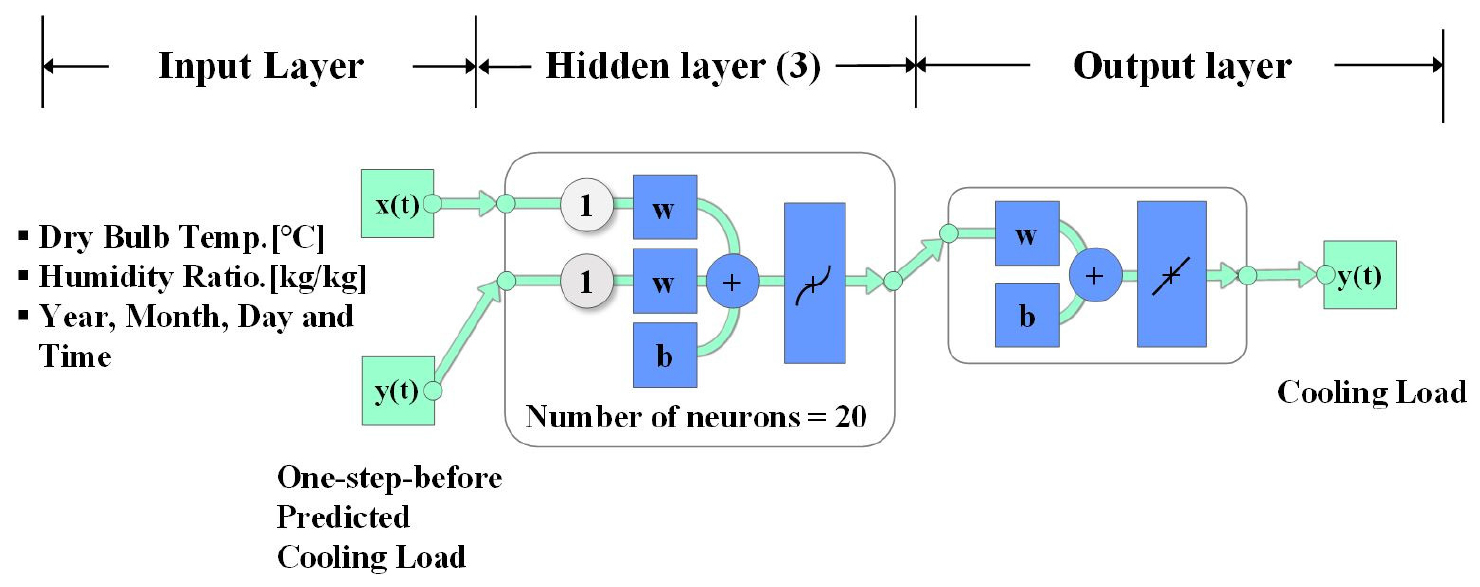
입력층의 구성은 학습을 위한 입력 변수들의 배열이다. 입력 변수의 개수 변화에 따라서 예측 성능에도 영향을 미치고 예측 결과도 변화하며, 예측하고자 하는 결과와 상관성이 없는 입력 변수들은 오히려 예측 성능을 저하하기도 한다(Seong et al., 2019). 따라서 본 연구에서는 업무용 건물의 냉방 부하 예측을 위한 입력층의 변수는 건물 부하에 일반적으로 영향을 미치는 외기 건구 온도, 외기 습도, 그리고 시간 데이터(Seasonally Data)로 구성하였다. 은닉층은 입력층으로부터 수신된 값을 이용하여 내부의 뉴런(neuron)을 통해 학습을 수행하는 층이다. 출력층은 학습된 결과를 예측값으로 출력하는 층이다. 출력값은 건물의 냉방 부하에 해당한다.
다층신경망 주요 입력 매개변수(Parameter) 설정
정확한 예측 결과를 위하여 다층신경망의 입력 매개변수를 다음과 같이 설정하였다. 다층신경망의 입력 매개변수는 크게 구조적 매개변수(Structural parameter)와 학습 매개변수(Learning parameter)로 구분한다. 구조적 매개변수는 신경망의 구조를 이루고 있는 은닉층의 수와 그 내부에 존재하는 뉴런(neuron)의 개수가 대표적인 구조적 매개변수이며 은닉층과 뉴런은 실제 학습이 이루어지는 곳으로 그 수에 따라 학습 용량이 결정된다. 학습 매개변수는 Epoch와 학습에 사용되는 데이터의 크기(Training Data Size)가 대표적 학습 매개변수이며 Epoch는 학습 단위로서 1회가 갖는 의미는 전체 데이터세트를 완전히 한 번 통과하는 것을 의미한다(Kim et al., 2020). 입력 매개변수의 변화에 따라서 신경망 모델의 예측 정확도가 변화하기 때문에 다층신경망 모델의 예측 정확도 향상을 위한 입력 매개변수의 조정과 최적화하는 방안이 필요하지만 본 연구에서는 앞서 수행된 연구(Kim et al., 2019a)에서 최적화된 값을 활용하였다. 학습에 사용되는 데이터의 크기는 기존의 연구(Kim et al., 2019b)에서 제시한 가장 일반적인 정확도를 갖는 70%로 설정하였다. 다층신경망의 학습을 위한 주요 입력 매개변수의 설정값을 정리하면 Table 1과 같다.
Table 1.
Values of structural parameters and learning parameters
| Division | Condition | |
| Structural parameter | Number of hidden layers | 3 |
| Number of neurons | 20 | |
| Learning parameter | Epochs | 100 |
| Training Data Size | 70% | |
신경망 학습을 위한 데이터 생성
본 연구에서는 다층신경망의 학습을 위한 데이터를 앞서 수행한 연구들 (Seong et al., 2020; Lee et al., 2021)과 같이 시뮬레이션의 결과로 생성된 데이터를 활용하였다. 시뮬레이션 데이터를 사용하는 경우는 실제 건물에서 장기간 데이터의 수집이 어려운 경우이다. 시뮬레이션은 업무용 건물의 부하특성을 잘 나타낼 수 있는 표준건물을 이용하였다. 업무용 표준건물은 DOE의 Building Energy Codes Program (Field et al., 2010; Building Energy Codes Program, 2022)의 표준건물 중에서 Commercial Prototype Building Models의 Middle Office Building (Field et al., 2010; Deru et al., 2011)을 이용하였다. Figure 2는 Middle Office Building을 모델링한 그림이다.
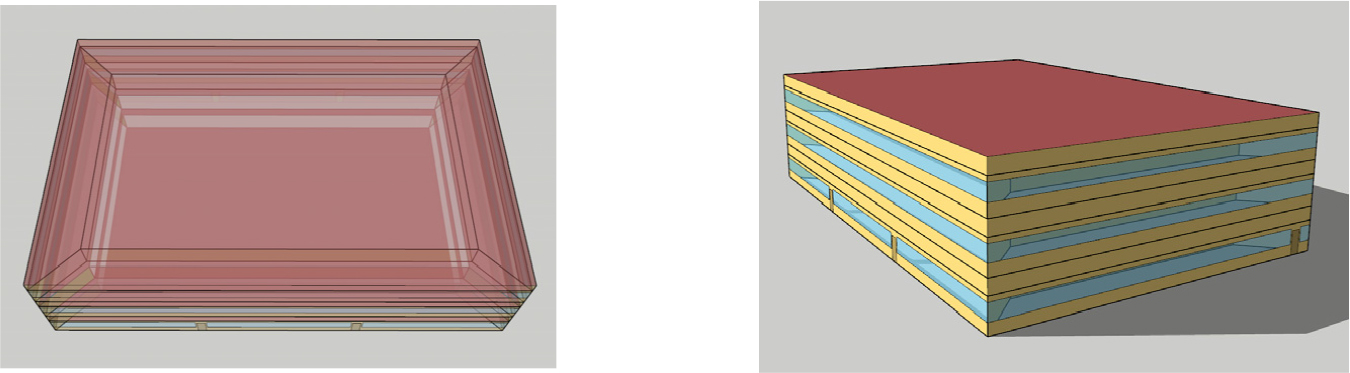
시뮬레이션 대상인 Commercial Prototype Building Models의 Middle Office Building은 3층의 건물로 내부(Interior zone)와 외부(Perimeter zone)로 구분된다. 건물의 열적 성능은 일부 조건들이 국내의 실정과 맞지 않는 부분들이 있어 외벽과 최상층 지붕의 열관류율 및 창호의 성능은 건축물의 에너지절약설계기준(Ministry of Land, Infrastructure and Transport, 2017)의 중부 2 지역 기준으로 변경하였다. 시뮬레이션을 위한 기상 데이터는 서울지역의 기상 데이터를 활용하였다. 시뮬레이션을 통해 건물의 냉방 부하, 외기 건구 온도, 외기 습도를 출력하였으며 데이터의 생성 시간 단위(timestep)는 1시간으로 하였다. 전체 시뮬레이션 기간은 연중 냉방 기간에 해당하는 4월 1일부터 10월 31일까지 데이터를 다층신경망의 학습데이터로 활용하며 데이터는 5,136세트이다. Table 2는 학습데이터 생성을 위한 표준건물 시뮬레이션의 주요 조건을 나타낸다.
Table 2.
Simulation condition of reference building (Middle office building)
데이터 전처리 방법과 예측 성능 평가
데이터 전처리 방법
데이터 전처리는 일반적으로 다층신경망과 같은 데이터 기반의 기계학습을 수행하는 경우 결과의 품질을 향상하기 위해 학습에 사용되는 입력데이터를 가공하는 행위를 일컫는다(Joo et al., 2000). 데이터의 단순 가공뿐만 아니라 데이터의 분석, 처리 과정 등 활용하기에 적합한 형태로 만드는 모든 과정이 이에 해당된다. 활용하기 위해 수집된 데이터들은 정확한 데이터들도 존재하지만, 데이터의 특성, 수집 방법 등에 따라서 품질이 달라진다. 데이터의 품질이 저하되는 주요 요인은 측정 과정에서 무작위로 발생하여 에러가 발생하는 잡음데이터(Noise data), 측정 장비의 오류나 영점이 조절되지 않아 발생하는 바이어스(Bias), 대부분 데이터와 다른 특성을 보이거나 임의로 발생하지 않고 특정한 조건 때문에 발견되는 이상치(Outlier), 측정 시 누락 되거나 상황이 발생하지 않아 생기게 되는 결측치(Missing values), 같은 값이지만 단위 등에 의해 다르게 표현되는 모순, 불일치(Inconsistent values), 측정 과정 또는 수집 과정에서 발생하는 중복데이터(Duplicate data) 등이 대표적이다(Tan et al., 2016).
데이터 전처리 방법은 데이터의 특성을 고려하여 결측치, 이상치, 모순, 불일치데이터를 제거하는 작업인 Data Cleaning, 2개 이상의 중복된 데이터를 병합하는 Data Integration, 데이터의 차원을 축소하여 데이터를 1자리 이내로 변환하거나 요약(Summarization), 정규화(Normalization) 집합화(Aggregation) 등을 수행하는 Data Transformation, 그 외에 방대한 데이터를 일정 시간 단위로 축소하는 Data Reduction과 Data Balancing 등이 있다(García et al., 2016). 본 연구에서는 냉방 부하가 갖는 데이터의 특성을 고려하여 휴일과 야간 시간에 공조시스템의 부하가 발생하지 않는 경우 0의 값을 제거하는 Data Cleaning 방법과 냉방 부하의 단위가 kW임을 고려하여 데이터의 차원을 변환하는 Data Transformation을 이용하였다. Data Cleaning의 결과는 냉방 부하가 발생하지 않는 0인 시간의 데이터를 제거하여 2,772개의 데이터세트로 변환하였다. Data Transformation의 결과는 자연수의 차원을 1의 소수점 두 자리까지로 변환하였다.
예측 모델의 성능 평가 방법
데이터 전처리 과정에 의한 다층신경망 모델의 냉방 부하 예측 성능은 ASHRAE (American Society of Heating, Refrigerating and Air-Conditioning Engineers) Guideline 14 (ASHRAE, 2014), FEMP (US DOE Federal Energy Management Program) (FEMP, 2008), IPMVP (International Performance Measurement and Verification Protocol) (IPMVP, 2010)의 M&V (Measurement and Verification) guideline에 따라 평가할 수 있다. ASHRAE, FEMP, IPMVP는 각각의 M&V 프로토콜(protocol)을 제시하고 있으며 Building Energy Model의 예측 정확도 기준을 정하고 있다. 각 예측 정확도에 대한 기준은 Table 3과 같으며 본 연구에서는 ASHRAE Guideline 14의 기준을 활용하여 예측 모델의 성능을 평가한다.
Table 3.
Acceptable calibration tolerance
| Calibration Type | Index | Acceptable Value * | ||
| ASHRAE Guideline 14 | FEMP | IPMVP | ||
| Monthly | MBE monthly | ± 5% | ± 5% | ± 20% |
| CvRMSE monthly | 15% | 15% | - | |
| Hourly | MBE hourly | ±10% | ±10% | ±5% |
| CvRMSE hourly | 30% | 30% | 20% | |
본 연구에서는 변동계수(CvRMSE, Coefficient of Variation of the Root Mean Square Error)와 평균편향오차(MBE, Mean Bias Error)를 모델의 예측 성능을 평가하는 지표로 사용하였다. CvRMSE는 분산을 고려하여 실제 값에 비해 예측값들의 흩어진 정도를 의미하고, MBE는 데이터의 편향성을 고려하여 예측값들이 목푯값에 얼마나 근접하게 군집을 형성하는지를 추적하여 오차를 파악하는 분석 지표이다. CvRMSE는 식 (1), MBE는 식 (2)를 이용하여 산출할 수 있다.
여기서, 은 데이터의 개수, 는 생성된 데이터의 값, 는 예측된 데이터의 값, 는 생성된 데이터의 평균, 는 독립변수의 수이다.
데이터 전처리 과정에 따른 다층신경망 모델의 정확한 예측 성능을 비교 평가하기 위해서 데이터 전처리 과정에 따른 냉방 부하의 예측을 각 20회씩 반복하여 수행한 후 산출된 예측 성능지표인 CvRMSE와 MBE의 최솟값, 최댓값, 평균값, 표준편차를 비교하였다.
결과분석
데이터 전처리를 수행하지 않은 예측 모델을 Case 1, 데이터의 차원만을 변환하는 Data Transformation 방법을 수행한 예측 모델을 Case 2, 데이터의 결측치를 제거하는 Data Cleaning 방법을 수행한 예측 모델을 Case 3, Data Transformation 방법과 Data Cleaning 방법을 병행한 예측 모델을 Case 4로 하였을 때 예측 성능을 비교한 결과는 다음과 같다.
데이터 전처리 과정에 따른 예측 결과
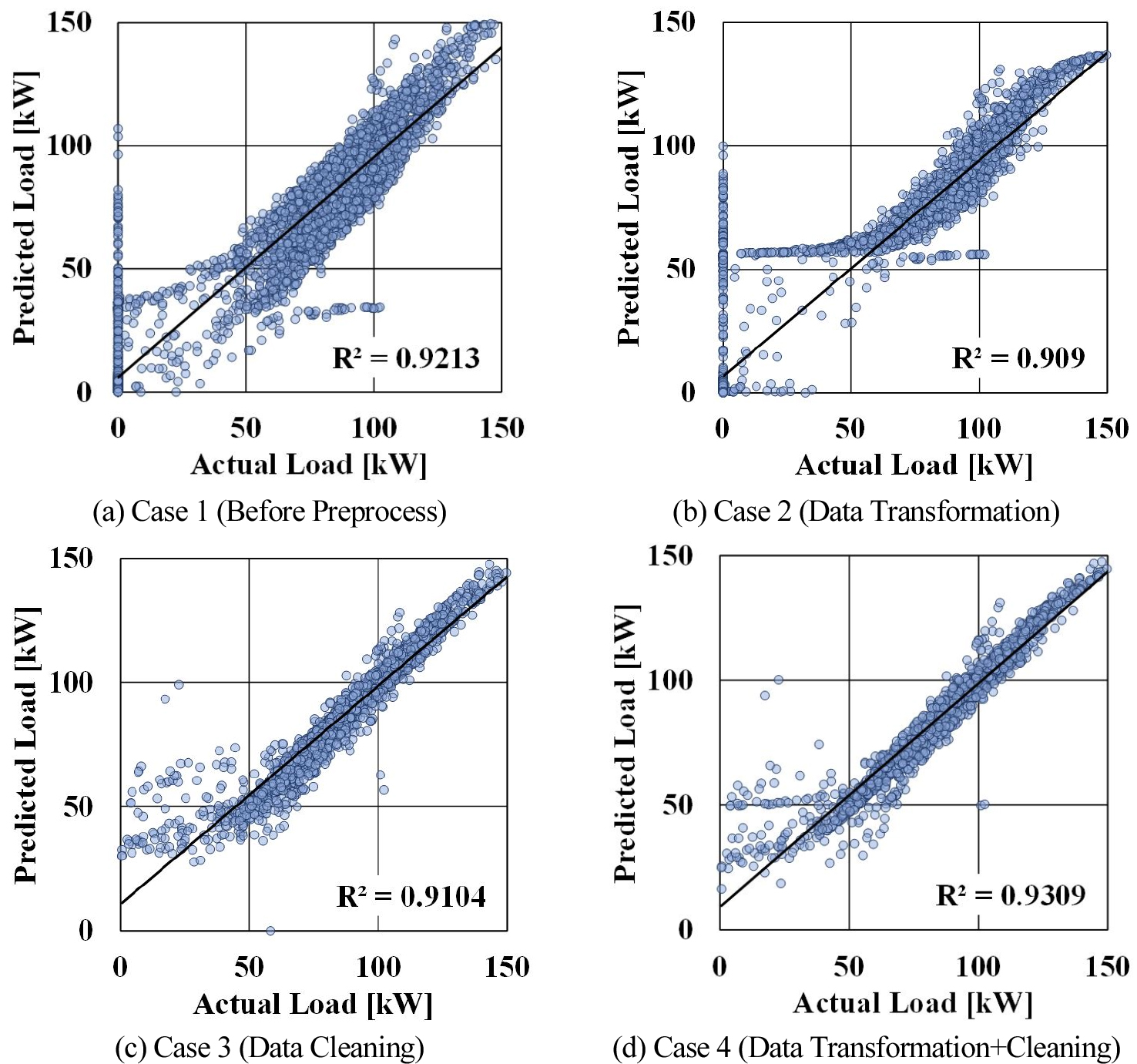
Figure 3은 데이터 전처리에 따른 냉방 부하의 예측 결과를 도식화한 것이다. 데이터 전처리 과정을 수행하지 않은 Case 1은 추세선을 중심으로 분포도 매우 넓으며, 특히 부하가 0인 경우에 예측값이 정확하지 않은 것을 확인할 수 있다. 100kW 이상의 고부하에서도 일치하지 않는 경우가 빈번하게 관찰된다. 데이터의 차원만 변환하는 전처리 과정을 수행한 Case 2는 Case 1에 비해 추세선을 중심으로 분포가 좁아지는 것을 확인할 수 있고 고부하 측의 예측값의 일치도가 비교적 조금은 개선된 것으로 보이지만 50kW 이하의 저부하 구간의 예측값들이 계속해서 일정값을 나타내는 결과가 관찰된다. 이는 차원을 1의 단위로 변환시키는 경우 0 이하의 소수점을 갖는 값들이 실제 값으로 재환산 되면서 나타나는 결과로 판단된다. 데이터의 결측치를 제거하는 Data Cleaning 방법을 수행한 Case 3은 부하가 0으로 되는 시간의 예측을 모델이 별도로 예측하지 않고 실제 부하가 발생하는 시간의 부하들만 예측 결과값으로 출력하기 때문에 예측값의 일치도가 향상되는 것을 확인할 수 있으며 실제 부하에 대한 예측값의 분포도 개선되는 것을 확인할 수 있다. Data Transformation 방법과 Data Cleaning 방법을 병행한 Case 4는 Case 3보다 고부하에서 예측값의 정확도가 상승하는 것을 관찰할 수 있으며, 추세선을 기준으로 한 예측값의 분포도 일부 개선된 것을 확인하였다. 모든 모델에서 결정계수(Coefficient of Determination R2)는 0.9 이상으로 독립변수인 실제 부하 값에 종속변수인 예측값이 90% 이상의 설명력을 가지고 있는 것을 확인하였다.
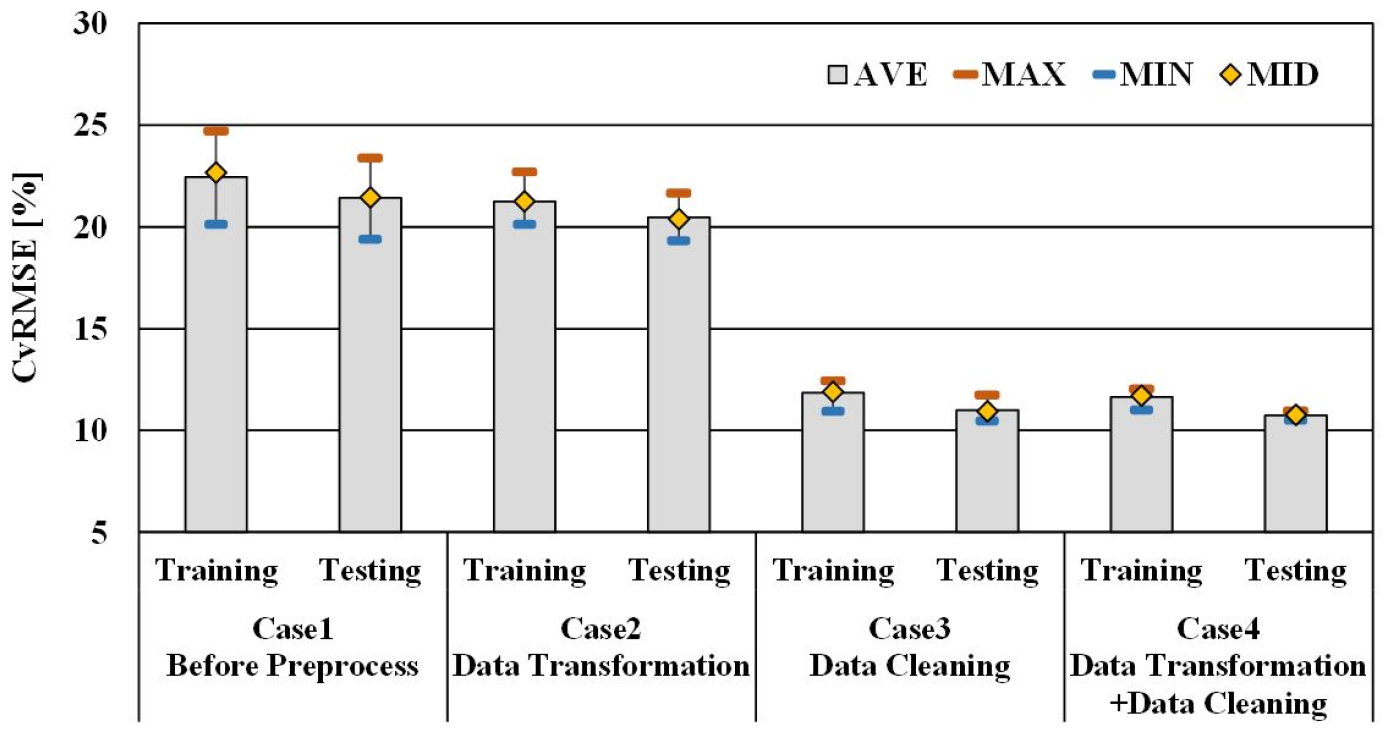
CvRMSE 지표에 의한 예측 성능 비교
Figure 4는 데이터 전처리에 따른 냉방 부하의 예측 결과에서 CvRMSE 지표에 의한 예측 성능을 비교한 결과이다. 데이터 전처리를 하지 않은 Case 1은 CvRMSE의 평균값이 훈련 기간(Training Period)에서 22.45%, 시험 기간(Testing Period)에서 21.47%로 모델의 예측 성능을 판단하는 ASHRAE guideline 14의 기준인 30% 이내로 정확성을 확보하는 것으로 나타났다. 데이터의 차원만 변환하는 전처리 과정을 수행한 Case 2의 CvRMSE의 평균값은 훈련 기간에서 21.25%, 시험 기간에서 20.47%로 Case 1에 비해 약 1%의 예측 성능이 향상되었다. 데이터의 차원을 변환하는 전처리 과정은 본 연구의 조건에서 부하 예측 모델의 CvRMSE 지표에 의한 예측 성능향상에 미치는 영향이 적은 것으로 판단된다. 데이터의 결측치를 제거하는 Data Cleaning 방법을 수행한 Case 3의 CvRMSE의 평균값은 훈련 기간에서 11.85%, 시험 기간에서 11.00%로 Case 1에 비해 약 11% 이상 Case 2에 비해서도 10% 이상 예측 성능이 향상되었다. 본 연구에서 사용한 데이터는 냉방 부하가 0이 되는 결측치를 제거하게 되면 전체 데이터세트의 개수는 5,136개에서 2,772개로 감소한다. 신경망 모델은 학습을 위한 데이터의 개수가 감소하면 예측 성능이 줄어드는 것이 일반적이다. 그러나 결측치를 제거함으로 인해서 불필요한 학습을 줄여줌으로 오히려 예측 성능이 크게 향상되는 것을 확인하였다. Data Transformation 방법과 Data Cleaning 방법을 병행한 Case 4의 CvRMSE의 평균값은 훈련 기간에서 11.64%, 시험 기간에서 10.74%로 가장 우수하였다. 데이터 전처리를 하지 않은 Case 1과 비교하면 훈련 기간과 시험 기간에서 CvRMSE 지표에 의한 예측 성능은 2배 가까이 향상되었다.
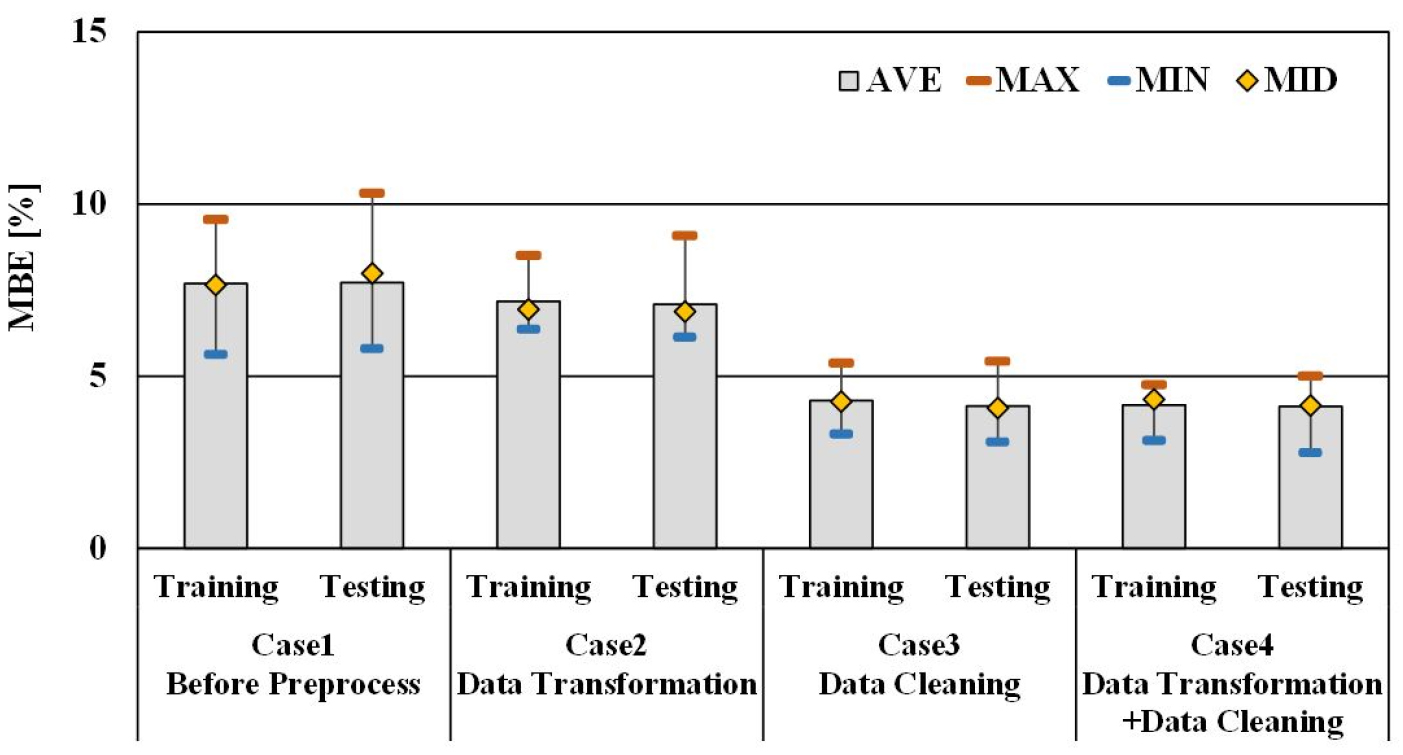
MBE 지표에 의한 예측 성능 비교
Figure 4는 데이터 전처리에 따른 냉방 부하의 예측 결과에서 MBE 지표에 의한 예측 성능을 비교한 결과이다. 데이터 전처리를 하지 않은 Case 1은 MBE의 평균값이 훈련 기간에서 7.68%, 시험 기간에서 7.71%로 모델의 예측 성능을 판단하는 ASHRAE guideline 14의 기준인 ±10% 이내로 정확성을 확보하는 것으로 나타났다. 데이터의 차원만 변환하는 전처리 과정을 수행한 Case 2의 MBE의 평균값은 훈련 기간에서 7.17%, 시험 기간에서 7.08%로 Case 1에 비해 0.5~0.6%의 예측 성능이 향상되었다. CvRMSE와 마찬가지로 데이터의 차원을 변환하는 전처리 과정은 본 연구의 조건에서 부하 예측 모델의 MBE 지표에 의한 예측 성능 향상에 미치는 영향이 매우 적은 것으로 판단된다. 데이터의 결측치를 제거하는 Data Cleaning 방법을 수행한 Case 3의 MBE의 평균값은 훈련 기간에서 4.29%, 시험 기간에서 4.13%로 Case 1에 비해 약 3.4~3.5% 이상 Case 2에 비해서도 약 2.9% 이상 예측 성능이 향상되었다. MBE 지표에 의한 예측 성능 평가 시에도 결측치 제거에 의한 예측성능향상을 확인하였다. Data Transformation 방법과 Data Cleaning 방법을 병행한 Case 4의 MBE의 평균값은 훈련 기간에서 4.16%, 시험 기간에서 4.11%로 가장 우수하였으나 Case 3과는 큰 차이가 나지 않는 것으로 나타났다. 데이터 전처리를 하지 않은 Case 1과 비교하면 훈련 기간과 시험 기간에서 MBE 값은 약 3.5%가 향상되었다.
종합 분석
데이터 전처리에 따른 냉방 부하의 예측 결과 중 20회 반복 학습에 의한 CvRMSE의 최댓값, 최솟값, 평균값, 표준편차는 Table 4와 같다. 앞선 Figure 4를 이용한 비교 분석에서 알 수 있듯이 데이터의 차원만 변환하는 전처리 과정보다 데이터의 결측치를 제거하는 전처리 과정이 예측 성능의 향상에 더 큰 영향을 미치는 것으로 나타났다. 전처리 과정에 따라서 표준편차도 감소하면서 일정한 예측 성능을 나타내는 것을 확인할 수 있었다. Case 4의 CvRMSE 결과가 Case 3보다 0.2% 정도 정확하지만, Case 4의 표준편차가 시험 기간에서 0.12로 매우 일정하고 안정적인 예측 결과를 출력하는 것을 확인하였다.
Table 4.
CvRMSE of load prediction result
데이터 전처리에 따른 냉방 부하의 예측 결과 중 20회 반복 학습에 의한 MBE의 최댓값, 최솟값, 평균값, 표준편차는 Table 5와 같다. 앞선 Figure 5를 이용한 비교 분석에서 알 수 있듯이 MBE를 이용한 지표도 CvRMSE와 마찬가지로 데이터의 차원만 변환하는 전처리 과정 보다 데이터의 결측치를 제거하는 전처리 과정이 예측 성능의 향상에 더 큰 영향을 미치는 것으로 나타났다. MBE의 결과는 Case 3이 Case 4보다 약 0.1% 정도의 높게 나타나지만, 표준편차는 Case 3의 시험 기간에서 0.50으로 더 안정적이고 일정한 예측 결과를 출력하였다. MBE만을 예측 모델의 성능지표로 활용하는 경우 데이터의 결측치를 제거하는 것만으로도 우수한 예측 성능을 확보할 수 있다.
Table 5.
MBE of load prediction result
결 론
본 연구에서는 다층신경망을 이용하여 건물의 냉방 부하를 예측할 때 데이터 전처리 여부가 예측 성능 향상에 미치는 영향을 알아보았다. 그 결과 신경망의 입력값으로 활용되는 데이터 전처리 과정을 통해 모델의 예측 성능과 정확도가 향상되는 것을 확인하였다. 데이터 전처리를 수행하지 않은 예측 모델 Case 1과 비교하여 데이터의 전처리를 모두 수행한 Case 4를 비교하였을 때 CvRMSE는 21.42%에서 10.74%로 예측 정확도가 향상되었으며, MBE는 7.71%에서 4.11%로 예측 정확도가 향상되었다. 예측 결과의 편차도 향상되어 일정한 결과를 출력하였다.
데이터의 차원만 변환하는 전처리 과정 보다 데이터의 결측치를 제거하는 전처리 과정이 예측 성능의 향상에 더 큰 영향을 미치는 것으로 나타났다. 그러나 데이터 규모가 훨씬 큰 입력 변수가 포함되었을 경우나 입력 변수의 종류가 더 많아질 경우 그리고 다른 데이터유형의 예측 모델에서는 상이한 결과가 나타날 수 있으므로 입력 변수의 다변화와 같은 추가적인 연구가 필요하다.
데이터 전처리 과정은 다층신경망을 포함한 데이터 기반의 예측 모델을 이용하여 건물의 부하를 예측할 때 모델의 예측 성능과 정확도를 향상하는 데 매우 유용한 방법으로 판단되며 데이터 전처리 과정이 예측 모델 성능에 미치는 영향 분석은 부하 예측 외에도 에너지소비량 예측과 그 외의 건물의 시계열 종류의 예측 모델의 성능향상에도 활용이 가능할 것으로 기대된다. 향후 업무용 건물 이외의 다른 용도의 건물 부하 패턴에 대한 예측에 관한 연구와 다층신경망을 이용한 부하 예측 모델에서 예측 성능의 향상을 위한 입력 파라미터의 조정 및 최적화 그리고 학습 알고리즘의 변경과 같은 추가 연구를 진행할 예정이다.
