

서 론
연구의 방법
음원 데이터 구성 및 수집
음원 데이터 전처리 및 Mel-Spectrogram 변환
CNN (Convolutional Neural Network) 모델 구조 및 학습
합성곱 계층(2D Convolutional Layer)
ReLU 활성화 함수
Max-Pooling 계층
Fully Connected Layer 및 Softmax 출력층
모델 구조의 특징
CNN (Convolutional Neural Network) 기반 수치 모델화 및 해석
Grad-CAM을 활용한 시각적 분석
FFT 기반 주파수 및 진폭 특성 분석
통합 분석의 의의
결과 해석 및 결론
모델 예측 결과 및 확률 계산
Grad-CAM 분석: 모델의 주목 영역 확인
FFT 분석: 주파수 및 진폭 특성 도출
결론: 모델 해석 및 응용 가능성
서 론
딥러닝 기술은 최근 다양한 분야에서 혁신적인 성과를 창출하며 현대 사회의 연구 및 산업 발전에 핵심적인 역할을 하고 있다. 자율주행, 의료 영상 분석, 자연어 처리, 스마트 홈 기술 등에서 딥러닝은 복잡한 데이터를 처리하고 고차원적인 패턴을 학습하여 실질적인 의사결정을 지원하는 데 있어 필수적인 도구로 자리 잡았다. 특히 지능형 환경 제어 시스템은 에너지 효율화, 사용자 경험 향상, 건강 증진을 목표로 딥러닝 기술을 적극적으로 활용하고 있으며, 이러한 시스템에서 재실자 행위 인식 기술은 사용자 중심의 맞춤형 환경을 제공하기 위한 핵심 구성 요소로 주목받고 있다.
재실자 행위 인식 기술은 사용자와 환경 간의 상호작용을 분석하여 실내공기질 관리, 에너지 소비 최적화, 안전한 실내 환경 조성 등 다양한 응용 분야에서 중요한 역할을 한다. 그러나 기존 기술은 몇 가지 한계를 가지고 있다. CO2 센서를 활용한 기술은 실내 CO2 농도를 기반으로 재실 여부를 감지하지만, 외부 환경의 변화(환기나 외부 공기 유입)에 민감하여 데이터의 안정성과 정확도가 저하될 가능성이 있다. 스마트 바닥 시스템은 사용자의 발걸음 패턴을 기반으로 행동을 분석할 수 있으나, 높은 설치 비용과 유지 비용이 요구되는 단점이 있다. 비디오 기반 기술은 높은 정확도를 제공하지만, 프라이버시 침해 우려와 데이터 처리의 복잡성이라는 문제를 동반한다. 이와 달리 음원 데이터를 활용한 접근은 비접촉식으로 환경 정보를 수집할 수 있으며, 비용 효율적이고 간단한 설치 과정을 통해 다양한 응용 분야에서 적용 가능성을 제공한다. 또한, 실내 환경 제어, 공기질 관리, 스마트 홈 자동화 등 다양한 분야에서 활용 가능하며, 기존 방식의 한계를 보완할 수 있는 혁신적 접근으로 평가받고 있다. 특히, Mel-spectrogram과 같은 비복원적인 데이터 변환을 활용할 경우 시각 정보와 달리 프라이버시 침해 우려를 대폭 줄일 수 있다는 점에서 기술적 가능성이 크다.
그러나 음원 데이터를 활용한 재실자 행위 인식 연구는 여전히 초기 단계에 머물러 있으며, 실제 응용을 위해서는 몇 가지 중요한 과제를 해결해야 한다. 첫째, 다양한 재실자 행위를 포괄하는 양질의 데이터를 확보하는 데 어려움이 있다. 둘째, 음원 데이터를 효과적으로 학습하고 분류할 수 있는 최적의 모델 구조와 학습 전략이 필요하다. 기존 연구에서는 재실자의 대표적인 행위를 “Boiling”(찌거나 삶는 조리 행위), “Frying”(굽거나 튀기는 조리 행위), “Vacuum”(진공청소기 사용 행위)로 정의하고 이를 분류하기 위한 다양한 딥러닝 모델을 개발하였다. CNN (Convolutional Neural Network), LSTM (Long Short-Term Memory), Bi-LSTM (Bidirectional Long Short-Term Memory), GRU (Gated Recurrent Unit) 모델을 비교한 결과, CNN이 95.0%의 정확도를 기록하며 가장 높은 성능을 보였다(Kim et al., 2024). 이는 CNN 모델이 음원 데이터 기반 행위 분류에 가장 적합한 모델임을 입증한 결과이다. 이를 바탕으로 본 연구는 모델의 내부 예측 메커니즘을 수학적으로 해석하고, 그 타당성을 시각화하는 후속 연구로서 수행되었다.
특히, Grad-CAM (Gradient-weighted Class Activation Mapping)을 활용하여 CNN 모델이 Mel-spectrogram 상의 어떤 영역에 주목하여 특정 클래스를 판단하는지 시각적으로 설명하고자 하였으며, FFT (Fast Fourier Transform) 기반 분석을 통해 각 클래스가 지닌 주파수 에너지 특성을 정량적으로 분석하였다. 이와 같은 해석적 접근은 단순한 예측 결과 이상의 정보를 제공하며, 모델의 신뢰성과 해석 가능성을 동시에 확보하는 데 목적이 있다.
궁극적으로, 본 연구는 딥러닝 기반의 음향 분류 모델이 실제 주거 환경에서 발생하는 소리를 효과적으로 인식하고 해석할 수 있는지를 평가함과 동시에, 그 작동 원리를 수학적 모델링과 시각화 기법을 통해 구조적으로 제시함으로써, 향후 지능형 환경 제어 시스템에 응용 가능한 기반 기술로 발전할 수 있는 가능성을 제시한다.
연구의 방법
본 연구는 실내 환경에서 발생하는 다양한 음원 데이터를 기반으로, 재실자의 주요 활동(boiling, frying, vacuum)을 분류할 수 있는 CNN 기반 딥러닝 모델을 개발하고, 해당 모델의 예측 원리를 시각적 및 수학적으로 분석하였다. 전체 연구의 흐름은 음원 데이터 수집 및 전처리, Mel-spectrogram 변환, CNN 모델 구성 및 학습, Grad-CAM과 FFT 기반의 해석으로 구성된다.
음원 데이터 구성 및 수집
모델 학습에 사용된 데이터는 총 1,883개의 음원 샘플로 구성되었으며, “Boiling” 460개, “Frying” 423개, “Vacuum” 1,000개의 데이터로 분류된다. 데이터는 실제 주방 환경에서 직접 녹음한 데이터뿐만 아니라 Freesound 및 YouTube와 같은 공개 온라인 소스를 통해 다양한 음향 조건을 반영할 수 있도록 수집되었다. 이를 통해 모델이 실내 환경의 다양한 소음 특성을 포괄적으로 학습할 수 있도록 하였다.
음원 데이터 전처리 및 Mel-Spectrogram 변환
수집된 음원 데이터는 CNN 모델의 입력으로 사용하기 위해 Mel-spectrogram으로 변환되었다. Mel-spectrogram은 시간 영역의 음원 데이터를 주파수 영역으로 변환하여 CNN 모델이 학습할 수 있는 2차원 데이터를 생성하며, 이를 통해 모델이 시간 및 주파수 간 관계를 학습할 수 있도록 한다. 변환 과정에서 Mel-spectrogram의 수학적 표현은 아래와 같이 정의된다.
여기서, 는 음원 신호의 Short-Time Fourier Transform (STFT) 결과이며, 는 Mel-Filterbank의 -번째 필터, 는 주파수, 는 시간을 나타낸다. 본 연구에서는 n_fft = 2048, hop_length = 512, n_mels = 64의 파라미터를 적용하여 Mel-spectrogram을 생성하였다. 생성된 Mel-spectrogram은 모든 입력 데이터의 크기를 균일하게 맞추기 위해 제로 패딩(Zero Padding)을 수행하여 최종적으로 64×64 크기의 행렬로 변환하였다.
CNN (Convolutional Neural Network) 모델 구조 및 학습
본 연구에서 제안된 CNN 모델은 음원 데이터를 Mel-spectrogram으로 변환한 2차원 행렬을 입력으로 받아, 재실자의 세 가지 대표적 활동인 “Boiling”, “Frying”, “Vacuum”을 분류하는 다중 클래스 분류 문제를 해결하도록 설계되었다. 모델은 다음의 주요 구조로 구성된다. 2D 합성곱 계층, 활성화 함수(ReLU), 풀링 계층(Max-Pooling), 완전 연결 계층(Fully Connected Layer), 그리고 Softmax 출력층이다.
합성곱 계층(2D Convolutional Layer)
합성곱 계층은 Mel-spectrogram 상의 지역적 패턴(특정 시간-주파수 대역의 에너지 분포)을 감지하기 위해 필터(또는 커널)를 이용하여 입력 특성 맵과의 합성곱을 수행한다. 수학적으로, 번째 합성곱 계층에서의 출력은 다음과 같이 정의된다.
여기서, 는 -번째 계층의 입력값, 는 번째 필터의 가중치, 는 바이어스 항이며, 는 번째 계층의 출력값이다. 이 연산을 통해 모델은 입력 데이터에서 지역적 특징(특정 주파수 대역의 패턴 등)을 학습하게 된다.
ReLU 활성화 함수
활성화 함수는 모델에 비선형성을 부여하여 복잡한 패턴 학습을 가능하게 한다. 본 연구에서는 연산 효율성과 학습 안정성이 높은 ReLU 함수가 적용되며, 이는 다음과 같이 정의된다.
이 함수는 음수 입력을 0으로, 양수 입력은 그대로 유지함으로써 활성화 값을 희소하게 만들어 과적합을 방지하는 효과를 가진다.
Max-Pooling 계층
Max-Pooling은 각 지역 영역에서 최대값을 추출하여 데이터 차원을 줄이는 연산으로, 주요 특징을 유지하면서 연산량을 줄이고 과적합을 방지하는 데 기여한다. 이 계층은 ReLU 이후에 배치되며, 시간-주파수 영역에서의 국소 특징을 추출한 후 공간 정보를 축소하여 다음 계층으로 전달한다.
Fully Connected Layer 및 Softmax 출력층
합성곱과 풀링을 거친 고수준 특징 벡터는 완전 연결 계층으로 전달되며, Softmax 함수를 통해 최종적으로 세 개의 클래스에 대한 확률 분포를 계산한다. Softmax 함수는 다음과 같이 정의된다.
여기서, 는 클래스 에 대한 Logit 값, 는 전체 클래스 수를 의미하며, 모든 클래스 확률의 총합이 1이 되도록 정규화한다. 이 확률을 기준으로 가장 높은 확률을 가진 클래스를 최종 예측값으로 선택한다.
모델 구조의 특징
이 구조는 Mel-spectrogram 기반 음원 데이터를 처리할 때 시간적·주파수적 패턴을 효과적으로 추출하고 분류할 수 있는 장점을 가지며, 실내 활동 인식이라는 본 연구의 목표에 적합한 구조로 평가된다. 특히 CNN은 정적인 이미지 형태의 입력(Mel-spectrogram)에 적합하며, 실시간 경량화된 분류 시스템 구현에도 용이한 특징을 갖는다.
CNN (Convolutional Neural Network) 기반 수치 모델화 및 해석
본 연구는 CNN 모델이 음원 데이터를 기반으로 재실자 행위를 분류할 때, 어떤 주파수 및 시간 영역의 특성을 기반으로 판단을 내리는지를 정량적·시각적으로 해석하고자 하였다. 이를 위해 Grad-CAM을 이용한 시각화 기법과 FFT를 이용한 주파수 도메인 분석을 병행하여, 모델 내부의 결정 메커니즘을 수학적으로 규명하고 해석 가능성을 높이고자 하였다.
Grad-CAM을 활용한 시각적 분석
Grad-CAM은 합성곱 신경망의 예측 결과에 대한 직관적인 설명을 제공하기 위해 사용되는 시각화 기법이다. 이 방법은 네트워크의 출력값에 대한 특정 클래스의 로짓 값과 관련된 마지막 합성곱 계층의 활성화 맵에 대한 그래디언트 정보를 활용한다. 이를 통해 모델이 입력 데이터의 어떤 위치 정보(주로 특징 맵의 공간 위치)에 주목했는지를 히트맵 형태로 시각화할 수 있다.
여기서, 는 마지막 합성곱 계층의 번째 채널의 출력 활성화 맵이고, 는 클래스 에 대한 로짓 에 대한 의 기울기를 평균화 값이다. 기울기 기반 가중치는 다음과 같이 계산된다.
여기서 는 활성화 맵의 전체 픽셀 수이며, ReLU 함수는 음의 기여도를 제거하여 주목 영역을 강조한다. 이를 통해 CNN이 음향 데이터의 시간-주파수 스펙트럼 중 어떤 구간에 집중했는지를 시각적으로 표현할 수 있으며, 특정 클래스(예: Vacuum)의 예측에 있어 특정 주파수 대역의 중요성을 확인할 수 있다.
FFT 기반 주파수 및 진폭 특성 분석
CNN 모델의 판단이 특정 주파수 대역에 민감하게 작동하는지를 수학적으로 입증하기 위해, 본 연구에서는 FFT 기반 스펙트럼 해석을 수행하였다. FFT는 시간 영역의 신호 을 주파수 영역으로 변환하여, 주기 성분 및 에너지 분포를 정량적으로 분석할 수 있는 고전적 도구이다.
여기서 는 주파수 성분 에 대한 복소수 스펙트럼이며, 은 샘플 수이다. 분석 결과, “Vacuum” 데이터의 경우 100–200 Hz 대역에서 에너지 분포가 강하게 나타났으며, 이는 Grad-CAM 히트맵 상에서도 해당 주파수 영역이 강조되는 결과와 일치하였다. 이를 통해 CNN 모델이 저주파 대역의 에너지 패턴을 “Vacuum” 클래스로 분류하는 결정 근거로 활용하고 있음을 확인하였다.
통합 분석의 의의
Grad-CAM과 FFT 분석을 결합한 이중 해석은 CNN 모델의 블랙박스 구조를 일정 부분 해체하며, 입력과 출력 사이의 논리적 연결 고리를 정량적·시각적으로 설명한다. Grad-CAM은 모델이 어떤 주파수-시간 영역에 주목했는지를 시각적으로 보여주고, FFT는 해당 영역이 실제로 높은 에너지를 갖는 신호 성분임을 수학적으로 증명한다.
이러한 분석은 단순히 정확도나 혼동행렬 기반의 평가를 넘어서, CNN 모델의 해석 가능성과 응용 신뢰성을 동시에 확보한다. 특히, 특정 클래스가 갖는 물리적 특성(예: 진공청소기의 저주파 소음)을 학습된 모델이 어떻게 내부적으로 인식하고 활용하는지를 밝힘으로써, 향후 다양한 음원 기반의 환경 제어 시스템 설계에 있어 구조적 투명성과 설득력을 제공한다.
결과 해석 및 결론
모델 예측 결과 및 확률 계산
제안된 CNN 모델에 “Vacuum” 클래스로 라벨링된 음원 데이터를 입력하여 예측을 수행한 결과, 해당 데이터는 “Vacuum” 클래스로 분류되었다. Softmax 함수 기반 예측 확률은 다음과 같이 “Boiling” 0.00917768, “Frying” 0.00411806, “Vacuum” 0.98670435로 나타났다. Softmax 함수는 각 클래스 에 대해 식 (4)과 같이 확률을 계산한다.
본 사례에서는 “Vacuum” 클래스의 Logit 값이 2.9405로 가장 높아, Softmax 결과 98.67%의 확률을 기록하였다. 이는 모델이 해당 데이터를 “Vacuum” 클래스로 강력히 예측했음을 의미한다.
Grad-CAM 분석: 모델의 주목 영역 확인
Grad-CAM 시각화를 통해 모델이 입력 Mel-spectrogram의 어느 부분에 주목했는지를 분석하였다. Figure 1과 같이 “Vacuum” 데이터의 Grad-CAM Heatmap은 주요 활성화 영역이 100–200 Hz의 저주파 대역에 집중되어 있음을 보여준다.
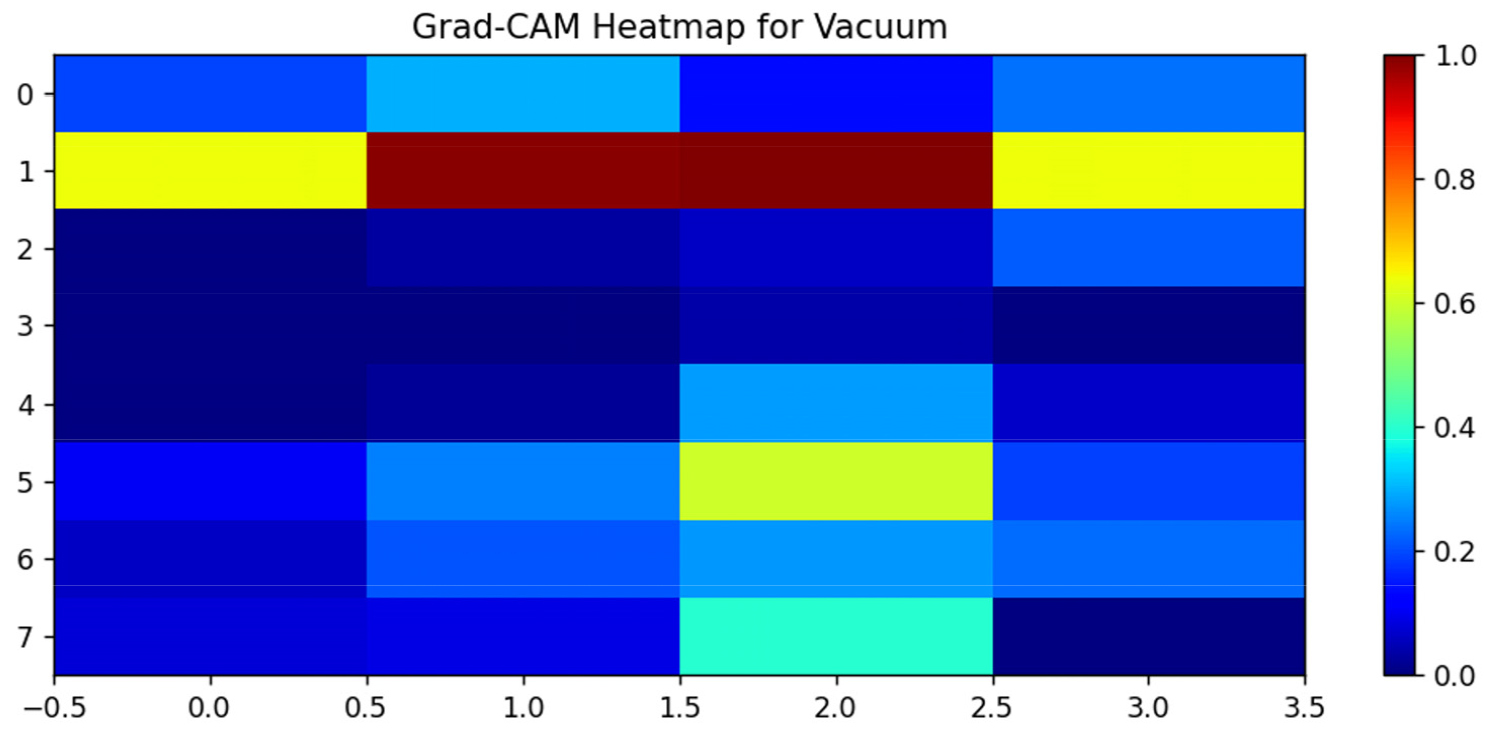
이는 저주파 영역의 특징이 “Vacuum” 클래스를 예측하는 데 핵심적인 역할을 했음을 시각적으로 입증한다.
FFT 분석: 주파수 및 진폭 특성 도출
음원 신호에 대해 FFT를 수행하여 주파수 성분별 에너지를 분석하였다. FFT는 시간 영역 신호 을 주파수 영역으로 변환하며, 식 (7)과 같이 정의된다.
분석 결과, “Vacuum” 데이터는 100–200 Hz 대역에서 높은 에너지 분포를 보였다. 이 특성은 Grad-CAM 분석과 일치하며, CNN 모델이 해당 주파수 대역의 특징을 학습하여 “Vacuum” 클래스를 예측한 것임을 수학적으로 뒷받침한다.
특히, “Vacuum” 클래스에 대한 에너지 집약 특성은 다음과 같은 수식으로 요약될 수 있다.
여기서, 는 주파수 에서의 에너지 크기이다.
결론: 모델 해석 및 응용 가능성
Grad-CAM과 FFT 분석을 통합하여 CNN 모델의 예측 과정을 시각적·수학적으로 해석하였다.
Grad-CAM은 입력 데이터 중 모델이 주목하는 영역을 시각적으로 강조하고, FFT는 해당 영역이 주파수적 특성상 의미 있는 에너지 패턴을 지닌 영역임을 정량적으로 확인해주었다.
본 연구를 통해 CNN 모델이 음원 데이터의 저주파 대역(100–200 Hz)에 존재하는 에너지 특성을 기반으로 “Vacuum” 클래스를 예측함을 입증하였다. Grad-CAM과 FFT를 활용한 시각적 및 수학적 분석을 통해 모델의 예측이 단순한 블랙박스 결과가 아니라, 입력 데이터 내 의미 있는 특성에 근거하여 이루어진 것임을 명확히 설명할 수 있었다. 이러한 접근은 CNN 기반 음원 분류 모델의 신뢰성과 해석 가능성을 동시에 강화하는 데 기여하였으며, 나아가 음원 기반 재실자 행위 인식 기술의 상용화 가능성을 높이고, 향후 지능형 건축 환경 제어 시스템 개발에도 실질적인 기반을 제공할 수 있을 것으로 기대된다.
