

서 론
민감도 분석 및 베이지안 보정의 이론적 고찰
민감도 분석
베이지안 보정
연구대상 개요 및 입력변수 선별
연구 대상 개요 및 취득 데이터 현황
변수의 다중공선성 분석
민감도 분석 결과
선별된 입력변수의 베이지안 보정
MCMC의 수렴 검증
베이지안 MCMC 결과
결 론
서 론
건물의 에너지 성능 향상 및 쾌적한 실내환경 제공을 위한 다양한 스마트 빌딩 요소 기술들이 개발되고 있으며 특히 건물 에너지 사용량 중 가장 많은 부분을 차지하는 공조부분에 대한 다양한 노력과 방안이 제시되고 있다.
고장발견진단(Fault Detection and Diagnosis, FDD)은 건물의 유지관리 측면에서 건물 각부에 발생하는 고장에 대한 정확한 감지와 진단을 통해 에너지 성능 향상을 도모할 수 있으며 이를 위해서는 건물 및 시스템 내의 다양한 물리적 변수 발생지점에 센서 설치와 안정적인 정보 전달을 위한 센싱 환경 구축이 요구된다. 그러나 건물 및 시스템 내에서 발생하는 변수 발생지점에 대한 접근의 문제, 부적절한 센싱 환경으로 인한 정보 획득의 어려움이 존재한다(Yoon, 2020).
가상센싱 기법은 물리적 센서를 대신하여 온도, 유량, 압력과 같은 데이터를 취득할 수 있고 머신러닝 알고리즘과 결합해 고장의 유무나 고장의 범위 등을 예측할 수 있다. 가상센서 개발을 위해서는 Data-Driven 방식에 입각한 머신러닝을 기반으로 하며 입력변수로 활용되는 Data-Set의 불확실성은 센서의 정확성을 저하시키는 주요 원인이 된다(Kim, 2013). 입력변수 Data-Set은 확정적으로 결정하기 어렵고 미지의 고장과 Error 등을 포함하므로 확률적인 특성이 강하며, 또한 입력변수에 내재된 불확실성은 곧 시뮬레이션 결과의 불확실성으로 귀결돼 건물의 성능 평가에 영향을 미친다(de Wit and Augenbroe, 2002; Macdonald et al., 2002).
불확실성의 해석은 확률적 접근을 통해 해결할 수 있으며, 수학자 베이즈의 확률 이론에 기반을 둔 베이지안 MCMC (Monte Carlo Markov Chain)가 대표적인 방법이다. 그러나 입력변수의 불확실성 해석은 변수가 나타내는 확률 분포 특성과 베이지안에 대한 충분한 지식이 없는 상태에서의 ‘가정’으로 이루어지는 경우가 대부분이며 이는 곧 건물의 에너지 분석 결과에 큰 영향을 주기도 한다(Youn, 2015). 더불어 불확실성 해석을 위해서는 대상으로 하는 모델(에너지 사용량, 열 성능치 등)과 이를 구성하는 입력변수의 조합에 따라 해석의 결과가 달라지기 때문에 해석 처리 속도 증가와 정확성 제고를 위해 모델(출력변수)에 대한 영향도가 높은 입력변수의 선별이 중요하며 대표적인 방법으로 민감도 분석(Sensitivity Analysis, SA)이 있다.
민감도 분석과 관련하여 Yu et al. (2020)는 건물 에너지 성능평가 요소의 개선을 위해 전역 민감도 분석(회귀분석, Sobol 분석)을 수행하였으며 연구 결과를 토대로 기존의 건물 에너지 성능 평가 항목들에 대한 가중치를 부여하였다. Kong et al. (2015)는 기존 건축물의 에너지 성능에 영향을 미치는 요소를 파악하기 위해 매틀랩을 통한 Morris분석과 Monte Carlo 시뮬레이션을 진행하였으며 그 결과로 전기 및 가스 사용량에 미치는 영향 요소를 각 5, 6개의 순위로 선별하였다. Oh et al. (2017)은 종합병원 병동부의 에너지 절감 외피 설계요소 도출을 위해 시뮬레이션 모델과 민감도 분석을 결합해 표준화회귀계수(Standardized Rank Regression Coefficient, SRRC)를 계산하여 난방 및 냉방에너지에 영향을 주는 변수를 선별하였다.
베이지안 MCMC와 관련, Kim et al. (2014)은 두 가지 타입의 HVAC 모델에 대한 불확실성 보정을 위해 Monte Carlo방법 중 하나인 Latin Hypercube Sampling 및 베이지안 MCMC를 활용하여 의사결정권자의 입력변수 선정이 모델 해석의 불확실성에 미치는 영향을 연구하였으며, Youn et al. (2014)은 건물 에너지 시뮬레이션을 위한 모델의 입력변수가 가지는 불확실성과 분석가의 주관적 판단이 에너지 모델의 성능 격차를 발생시키는 것을 인지하고 이를 정량화 할 수 있는 방안을 베이지안 MCMC를 통해 제시하였다. 더불어 Tian et al. (2018)은 건물의 에너지 분석을 위한 입력변수의 불확실성 보정과 민감도 분석을 Dempster-Shafer 이론을 적용하여 해석하였고, Calama-Gonzalez et al. (2021)는 건물 에너지 모델의 불확실성 보정을 위해 두 개의 테스트 실험모델 구축과 실험모델의 입력변수를 건물의 열 성능치, FCU로 한정하여 민감도 분석 및 NUTS 알고리즘 기반의 베이지안 MCMC를 통해 해석하였다.
이상의 연구를 포함한 국내외 많은 연구에서 입력변수의 불확실성 보정을 위해 민감도 분석을 통한 변수 선별과 베이지안 MCMC를 활용한 불확실성 보정을 진행하였고 연구 방법의 효율성 및 해석 결과를 검증하였다.
따라서 본 연구에서는 가상센서 개발을 위한 입력변수의 불확실성 보정을 위해 민감도 지수를 정량적으로 표현 가능한 Sobol분석을 통해 에너지사용량에 영향력이 높은 입력변수를 선별하고 베이지안 MCMC를 활용하여 입력변수의 모델 Parameter를 사전, 사후확률 분포로 나타내어 불확실성을 보정하였다.
민감도 분석 및 베이지안 보정의 이론적 고찰
앞서 언급한 바와 같이 건물의 고장발견진단을 위해서는 고장의 발생에 따른 건물 에너지 사용량 증가 등과 같이 건물의 성능 변화를 예측하는 것이 중요하다.
건물 에너지 사용량의 예측을 위해 에너지 시뮬레이션, Data-driven의 기계학습과 같은 방법들이 대두되고 있지만 다양한 입력변수의 단일 값으로 결정되기 어려우며 강한 확률적 특성을 가진다. 입력변수의 확률적 불확실성은 실제 시스템 거동과의 큰 차이를 유발하며 이를 해결하기 위한 방법으로 크게 수동보정, 결정적 보정, 확률적 보정이 있으며 그 중 입력변수의 확률적 특성을 고려한 확률적 보정이 대표적으로 사용된다.
확률적 보정의 대표적인 기법으로 베이지안 보정이 가장 많이 적용되며 베이지안 보정에서 입력변수의 증가는 변수의 개수에 상응하는 차원의 공간에 대한 탐색을 요구하기 때문에 연산 부하가 급격히 높아질 수 있다. 변수들의 적절한 사후분포를 구하기 위해서는 MCMC를 통해 얻은 표본들이 Markov-Chain의 Stationary 분포에 수렴하도록 수많은 반복 계산이 필요하다. 이때, 변수가 많아지면 탐색 공간이 기하급수적으로 증가하는 차원의 저주(Curse of Dimensionality)가 발생하고 연산부하를 줄이기 위해 MCMC 표본의 추출횟수를 줄이면 변수의 충분한 탐색이 이루어지지 않아 표본들이 Markov-Chain의 Stationary 분포에 충분히 근사해졌다고 확신하기 어려워진다.
민감도 분석
민감도 분석이란 한 모형(또는 모델)에서 취할 수 있는 가능한 값 모두를 대입해 값의 변화에 따른 결과를 분석하는 것으로, 본 연구에서는 베이지안 보정의 정확도 향상을 위해 입력변수 중에서 출력에 영향력이 높은 변수를 선별된 변수로 추출하기 위한 과정이 필요하며 이런 과정을 민감도 분석(Sensitivity Analysis)이라 칭하고 크게 Local 방식과 Global 방식으로 구분한다. Local 방식은 원안 대비 변화하는 민감도를 평가하는 반면 Global 방식은 전체 변수 공간(Variable Space) 내에서의 민감도 평가가 가능하므로 신뢰성이 높은 것으로 알려져 있다(Tian, 2013). Global 방식의 Sobol 방법은 Sobol 민감도 지수(Sensitivity Index, )를 통해 출력변수에 대한 입력변수의 민감도를 정량적인 수치로 표현할 수 있다는 장점으로 건물 에너지 모델과 관련한 대표적인 기법으로 사용된다.
식 (1)은 Sobol방법의 민감도 지수이며 여기서, 는 민감도지수, 는 기댓값, 는 분산, 는 출력변수, 는 입력변수로 입력변수에 대한 출력변수 분산의 기댓값을 출력변수의 전체 분산으로 나눈 값으로 정의한다.
베이지안 보정
베이지안 보정은 수학자 베이즈(Bayes)의 베이지안 확률 이론에 기반을 두며 미래의 어떤 사건이 발생할 확률은 과거 같은 사건이 발생한 확률을 참조하여 구할 수 있다는 것을 이론화 한 것이다. 베이지안 추론의 첫 단계는 추정하고자 하는 입력변수의 불확실성을 사전 지식(Prior Knowledge)을 이용하여 확률 분포로 표현하는 것이며 다음의 식 (2)의 베이즈 이론을 통해 사후확률 분포로 업데이트 한다.
여기서 는 입력변수의 집합, 는 실제 시스템의 실측 데이터, 는 입력변수의 사후확률분포, 는 우도함수, 는 입력변수의 사전확률분포, 는 정규화 상수를 의미한다.
식 (2)의 사전확률분포와 우도함수를 통한 사후확률분포의 계산에서 입력변수에 대한 정보가 없거나 적은 경우 사전확률분포는 Central Limit Theorem을 기반으로 정규분포로 정의하는 것이 일반적이며, 평균값은 0, 표준편차는 측정치의 표준편차 또는 랜덤오차의 범위를 바탕으로 정의한다. 즉, 최소한의 정보를 나타내는 정규분포를 활용함으로써 정보적 사전확률분포 활용에 따른 변수의 불확실성 보정의 정확성이 높은 것으로 나타난다.
우도함수는 변수()가 주어질 때 기준값()가 도출될 가능성을 나타내며, 다음의 식 (3)과 같이 평균이 0이고 표준편차가 인 가우시안 분포를 바탕으로 이루어진다.
여기서, 는 데이터 세트(는 데이터 세트의 총 개수), 는 정규분포의 표준편차이다.
한편, 본 논문에서는 베이지안 보정을 위한 개발 프로그램으로써 Python을 사용하며 베이지안 MCMC진행을 위한 프로그래밍 패키지로 Pymc3를 사용하였다. Pymc3는 사용자로 하여금 다양한 수치 방법을 사용하여 베이지안 모델을 Fitting할 수 있는 프로그램이며 간단한 모델링으로 기능적 사용 문제에 대한 부담을 줄여 사용자의 통계적, 학술적 이슈에 집중할 수 있도록 한다(PyMC3, 2018).
연구대상 개요 및 입력변수 선별
연구 대상 개요 및 취득 데이터 현황
본 논문에서는 경기도에 위치한 건물의 1시간 단위 하계(7~8월, 62일)데이터 1,488개를 활용하였다. 해당 건물은 Figure 1과 같이 52개의 수랭식 VRF 실외기가 6개의 셀(Cell)로 이루어진 하나의 그룹형 냉각탑 시스템과 연동되어 있으며 3개의 셀이 하나의 냉각탑을 구성한다.
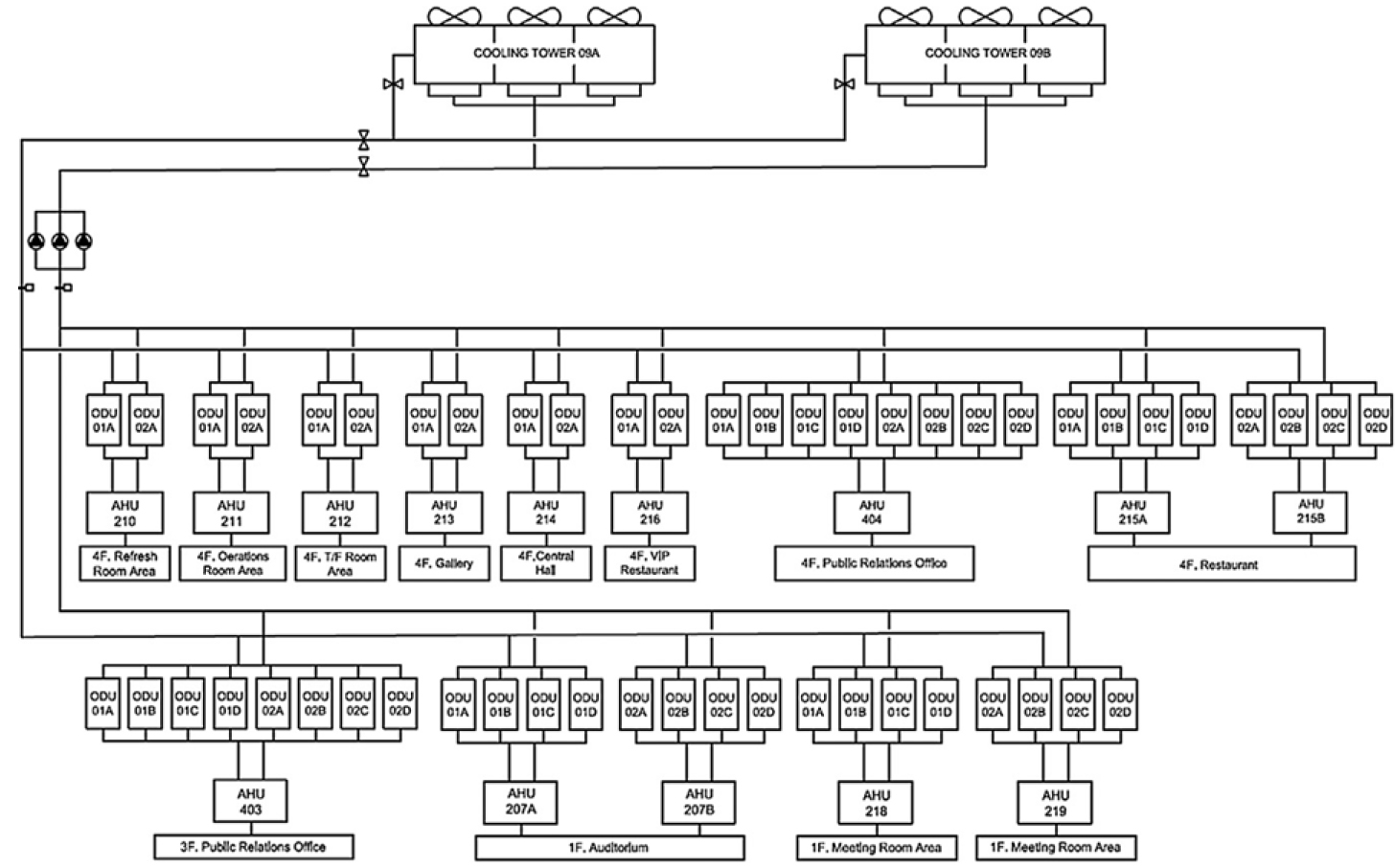
HVAC 시스템은 공조기, 냉각탑, 펌프로 구성되며 그 중 공조기에서 취득되는 데이터를 활용하여 민감도 분석 및 베이지안 보정을 수행하였다. 14대의 공조기에서 총 55개 항목의 데이터가 취득되며 그 중 데이터 결손이 발생한 3개 Point의 데이터를 제외한 20개의 공통 항목(x1~x20)과 종속변수인 에너지 사용량을 y로 나타내었고 민감도 분석을 위한 Min, Max 값은 Table 1과 같다.
Table 1.
List of parameters with variation
변수의 다중공선성 분석
Sobol 방법을 포함한 Global Sensitivity Analysis는 ‘입력변수가 독립적이다’라는 가정이 우선된다. 이는 상관성이 높은 변수를 사용하게 될 경우 자기상관(Correlation)에 의한 모델의 정확성 문제에 대한 이슈가 있을 수 있기 때문이다.
따라서 본 논문에서는 민감도 분석에 앞서 x1~x20의 변수들의 다중공선성을 평가할 수 있는 분산팽창요인(Variance Inflation Factor, VIF)을 활용하였다. 다중공선성이란 여러 변수들에 존재하는 공통적인 선형 관계를 의미하며, 대표적인 평가지표로 VIF를 통해 확인할 수 있으며 일반적으로 값이 10을 초과하는 경우 변수에 다중공선성이 있는 것으로 판단한다.
Table 2는 Table 1에서 제시된 변수를 VIF를 통해 다중공선성을 평가한 것이다. VIF가 10을 초과하는 변수 제거를 통해 12개의 변수에 대해 각 10미만의 VIF를 확보하였으며 0.0001 ~ 7.3402 수준인 것으로 나타났다.
Table 2.
List of variation by VIF
민감도 분석 결과
민감도 분석을 위해서는 변수들의 특성을 나타내는 모델(에너지 시뮬레이션 모델, 함수 등)이 필요하다. 본 논문에서는 다양한 입력변수의 구성과 모델 파라미터의 탐색에 대한 계산부하가 커지는 이유로 인공신경망(Artificial Neural Network, ANN) 대리모델을 활용하였다. 이는 에너지 시뮬레이션 모델과 관련한 물리식으로 해석이 가능하나 본 연구에서 특정한 AHU의 범위를 HVAC으로 확장할 경우 발생할 수 있는 이슈를 사전에 처리하기 위함이다. ANN 개발을 위해 Python의 Scikit-Learn 패키지를 사용하여 구현하였으며 모델 최적화를 위한 Hyper-Parameter는 Hidden Layer: 10, Neuron: 50, Activation Function: Relu, Optimizer: Adam을 사용하였고 모델의 과적합 방지를 위해 Early-Stopping 활성화 및 최대 학습 횟수는 2,000회로 지정하였다.
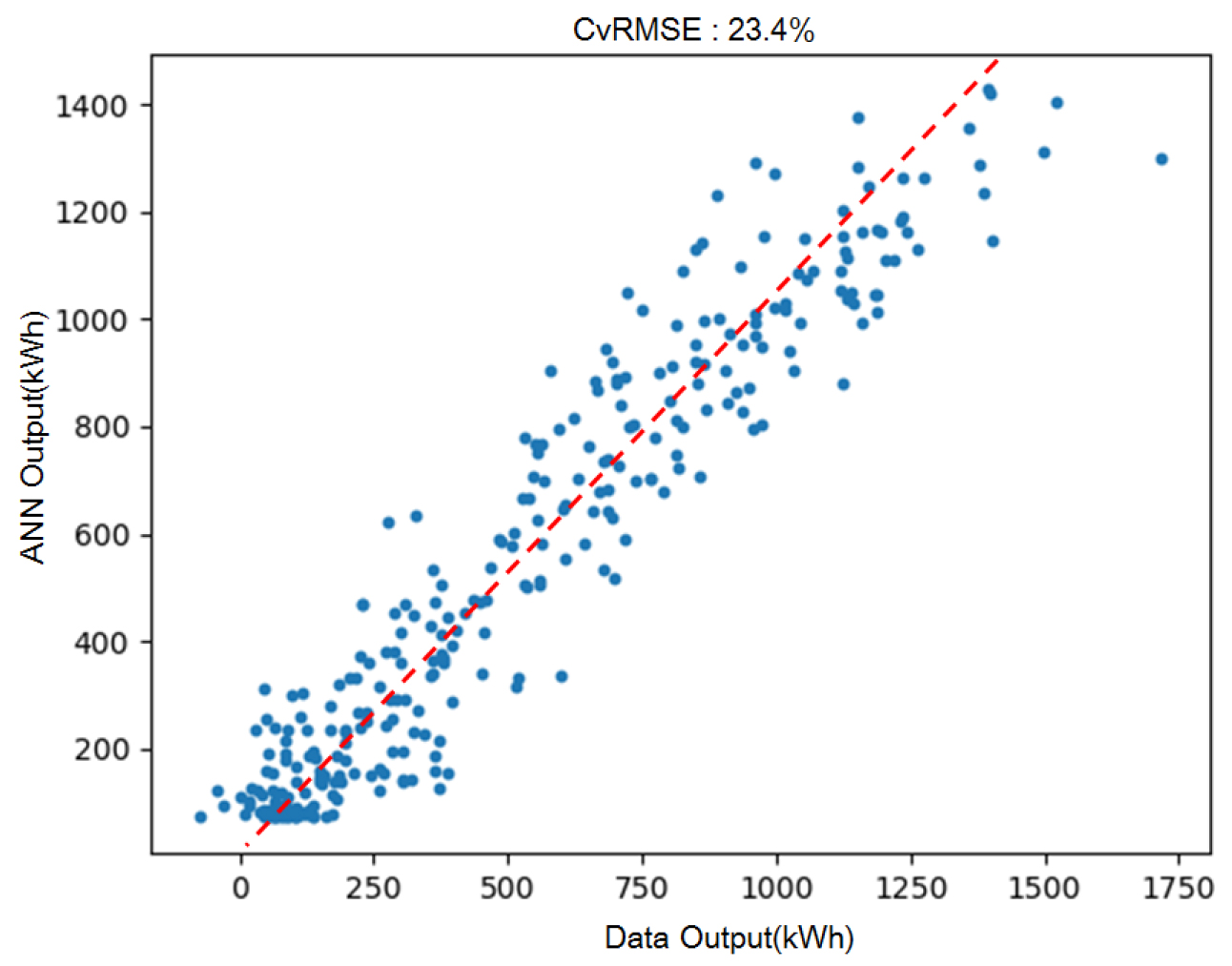
Figure 2를 통해 학습된 모델의 정확성을 나타내는 R2 값은 0.91이며 ANN을 통해 예측한 결과값과 실측 데이터 간의 CvRMSE는 23.4%로 시간별 데이터의 시뮬레이션 값과 실측값의 정확성 지표로 활용되는 CvRMSE 30% 미만의 기준에 충족하므로 대리모델의 정확성이 확보된 것으로 판단하였다.
민감도분석은 Python의 SALib패키지를 이용하여 정량적인 지수로 표현 가능한 Sobol방법을 활용하였으며 입력변수의 총 민감도는 해당 입력변수에 대한 단일 효과 및 교호작용의 총합으로 정의된다(Saltelli et al, 2008). 교호작용이란 출력변수에 대한 입력변수들 간의 상호작용을 의미하며 본 논문에서는 Monte-Carlo 시뮬레이션을 기반으로 하는 식 (4)의 Saltelli’s Sampling Scheme을 사용하였다.
Table 3은 Sobol을 활용한 민감도 분석의 결과를 소수점 넷째 자리로 나타낸 것이다. x1~x20중 총 민감도 지수인 Si의 상위 6개를 선정하였으며 유효전력량, 댐퍼개도, 외기온도, 필터차압 등의 항목으로 나타났다. 이를 통해 선별된 입력변수들이 종속변수의 불확실성에 미치는 영향도를 확인할 수 있으며, 선별된 입력변수의 불확실성 보정이 곧 에너지 사용량의 불확실성을 보정하는 것으로 귀결된다.
Table 3.
Selection parameter through sensitivity analysis
Sobol Method는 변수의 중요도를 도출하는 것과 더불어 변수간의 교호작용을 관찰하는 목적으로 사용된다. 변수간의 교호작용은 Sobol의 n차(일반적으로 2차까지 확인) 교호작용 민감도 지표를 통해 확인할 수 있으며 이로인해 총 민감도 지수의 합은 1을 초과하게 된다. 본 연구에서 선별된 변수의 민감도 지수의 합은 1.03로 이는 외기온도-급기습도-환기습도 설정-댐퍼개도 등의 변수에서 교호작용이 발생한 이유인 것으로 사료된다.
선별된 입력변수의 베이지안 보정
MCMC의 수렴 검증
베이지안 MCMC의 결과 분석에 앞서 MCMC의 수렴이 올바르게 진행되었는지에 대한 검증이 필요하다. MCMC 수렴 검증은 Gelman에 의해 최초 고안된 R-hat 값으로 추정할 수 있다. 이는 MCMC의 수렴정도가 동일한 길이 n의 m체인에 대한 내부 결과의 안정성에 기반하며 1에 가까운 값은 제안분포에 대한 수렴을 나타내며 1.1보다 큰 값은 부적절한 수렴을 나타낸다(Gelman and Rubin, 1992). 다음의 Table 4는 선별된 변수들의 모델 Parameter에 대한 R-hat값을 나타낸 것이며 MCMC의 수렴이 원활히 이루어진 것을 확인할 수 있다.
Table 4.
R-hat value according to MCMC
베이지안 MCMC 결과
베이지안 보정은 변수의 불확실성을 확률분포의 형태로 표현하고 이를 몬테카를로 시뮬레이션으로 업데이트한다. 먼저 대상 변수의 적정 제안분포(균등분포, 정규분포, 삼각분포 등)를 설정하고 분포에 대한 모델 Parameter를 설정한 뒤 MCMC를 통해 모델 Parameter를 추정한다.
주어진 최소한의 정보를 활용하여 사후확률분포를 Fitting하기 위해 본 연구에서는 변수별 모델 Parameter의 제안분포를 정규분포로 지정하고(이때, 최소한의 정보를 아는 경우 모델 Parameter 정보를 활용하고 모르는 경우 제안분포의 평균은 0, 표준편차는 데이터가 존재하는 범위 내로 지정) 변수가 가지는 Noise를 양(+)의 값을 나타내는 Halfcauchy로 설정하였다. Halfcauchy 사용에 따른 Scale Parameter는 ‘5’로 지정하였다. 이는 Cauchy와 달리 Peak점을 ‘0’으로 기준 하는 Halfcauchy는 Location Parameter의 설정이 불필요하며 비교적 낮은 Scale Parameter 설정으로도 원하는 Parameter 탐색이 가능하기 때문이다.
MCMC는 일반적으로 Metropolis-Hastings 알고리즘이 사용되나 Hyper-Parameter 조정에 대한 문제해결을 위해 본 연구에서는 NUTS알고리즘을 사용하였으며, Draws와 Tune, Target_Accept를 각각 3,000, 1,000, 0.9로 설정하였다.
Figure 3과 Table 5는 선별된 변수들에 대한 모델 Parameter의 Prior와 Posterior를 KDE (Kernel Density Estimation) Plot 및 평균과 표준편차를 통해 나타낸 것으로 변수가 가지는 불확실성이 MCMC를 통해 보정된 것을 확인할 수 있다. KDE란 밀도추정의 Non-Parametric한 방법 중 하나로 적분값이 1인 양의 함수로 정의되는 커널 함수를 데이터 개수만큼 모두 더한 뒤 데이터 개수로 나눈 것으로 다음의 식 (5)와 같이 표현된다. 여기서 n은 데이터 개수, K는 커널함수, X는 입력 데이터, h는 커널함수의 파라미터로 그래프의 형태가 완만할수록 큰 값, 조밀할수록 작은 값을 나타낸다.
KDE Plot은 추정된 모델 Parameter에 대한 평균과 표준편차로 Sampling 범위를 국한하고 Random Sampling을 MCMC 횟수와 동일하게 진행하여 Prior 및 Posterior을 산출하였다.
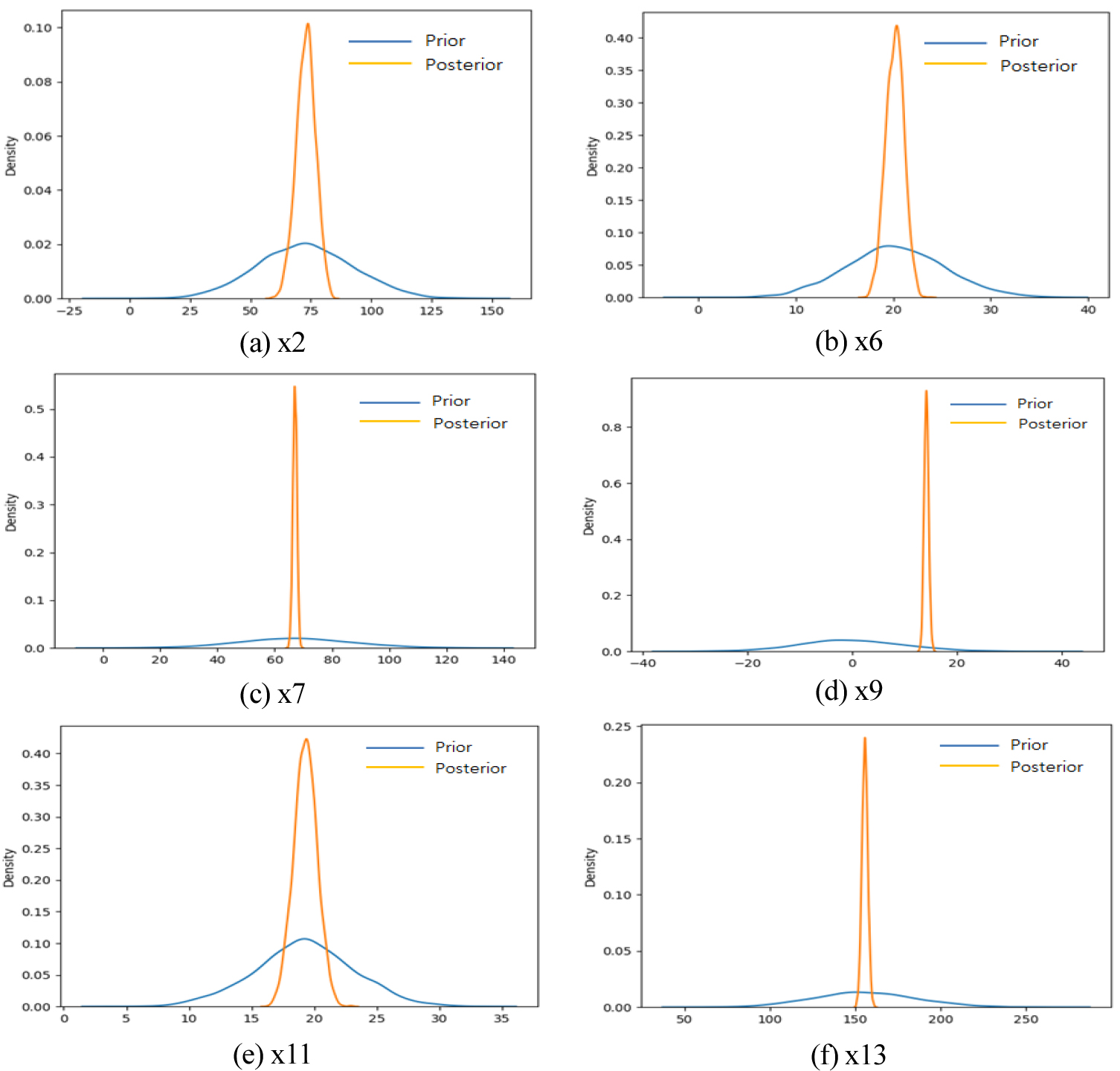
Table 5.
Average and Standard deviation of prior and posterior
| ID | Prior | Posterior | ID | Prior | Posterior | ||||
| x2 | 73.1 | 20 | 73 | 4 | x9 | 0 | 10 | 14.2 | 0.43 |
| x6 | 20.3 | 5 | 20.3 | 0.9 | x11 | 19.3 | 4 | 19.3 | 0.92 |
| x7 | 67.1 | 20 | 67.1 | 0.7 | x13 | 155.5 | 30 | 155.5 | 1.7 |
MCMC의 결과인 Figure 3과 Table 5로부터 x2~x13에 대한 불확실성이 보정된 것을 확인할 수 있다. 그래프의 중심을 기준으로 밀도가 낮고 Tail이 긴 경우 모델 Parameter의 불확실성이 큰 것으로 볼 수 있으며 밀도가 높고 Tail이 짧은 경우 불확실성이 적은 것으로 해석할 수 있다.
결 론
본 논문에서는 입력변수의 불확실성이 건물의 성능 평가에 미치는 영향에 대한 이슈도출과 이를 해결하기 위해 인공신경망 대리모델을 활용한 Sobol 민감도 분석을 실시하고 선별된 변수들에 대한 베이지안 보정과 검증을 통해 불확실성 해석을 진행하였다.
주요 결과로써 건물 에너지 사용량 모델의 단점이 될 수 있는 다양한 입력변수와 모델 Parameter의 계산부하 처리를 위한 민감도 분석을 CvRMSE 값이 23.4%인 인공신경망 대리모델을 통해 해결하였고, 실측 데이터에서 주어진 최소한의 정보를 활용하여 선별된 변수들에 대한 모델 Parameter 선정 및 NUTS 알고리즘을 적용한 베이지안 MCMC를 통해 입력변수의 불확실성을 보정하고 R-hat 값을 통해 MCMC의 수렴을 검증하였다. 사전/사후 분포를 통해 살펴본 모델 Parameter의 보정결과 6개의 선별된 변수들의 불확실성이 보정되었다.
한편, 본 연구에서는 민감도분석을 위한 대상을 인공신경망 대리모델로 선정하였다. 추후 연구대상을 HVAC으로 확장할 경우 발생할 수 있는 이슈를 사전에 처리하기 위함이었으나 간단한 First principle 모델을 통해 확인이 가능할 것으로 사료된다.
따라서, 이후의 연구에서는 First principle 모델과 인공신경망 대리모델의 적용에 따른 학습효과에 대해 다루어져야 할 것이다. 또한 본 논문에서 진행된 베이지안 보정은 입력변수와 종속변수의 관계를 선형적으로 나타내는 방법이며, 건물 에너지 사용량에 대한 입력변수들의 복합적인 불확실성을 해석할 수 있는 비선형 베이지안 보정에 대한 추가 연구가 필요할 것으로 사료된다.
끝으로 해당 연구결과를 토대로 건물 HVAC에서 발생할 수 있는 고장에 대한 정밀한 예측과 진단을 위한 가상센서 개발이 가능할 것으로 판단되며 추후 연구를 통해 진행할 계획이다.
