

서 론
측정개요
기준 건물 파라미터 식별
EnergyPlus 모델 생성
결과 및 토의
군집 분석을 통한 참조 건물 기하학적 형상 결정
EnergyPlus 모델 생성
한계점 및 향후 연구 방향
결 론
서 론
건물은 전 세계 에너지 소비의 약 30%, 에너지 관련 온실가스 배출의 약 26%를 차지하고 있다(IEA, 2022). 도시가 성장함에 따라 에너지 수요는 급격히 증가하며, 특히 냉난방 부문에서 그 수요가 두드러진다. 이러한 에너지 수요 증가는 탄소 배출을 가중시키고 도시 기반 시설에 큰 부담을 주며, 보다 효율적인 에너지 관리 전략의 필요성을 야기한다. 한국 역시 서울과 경기도와 같은 대도시권을 중심으로 빠른 도시화가 진행되고 있으며, 특히 업무 시설 등 에너지 소비에서 큰 비중을 차지하는 상업 부문에서 유사한 과제에 직면해 있다.
건물 에너지 모델링(BEM, Building Energy Modeling) 도구는 건물의 에너지 성능을 예측하는 데 널리 활용되며, 도시 계획자와 엔지니어들이 효율적인 에너지 전략을 수립하는 데 도움을 준다. 이러한 시뮬레이션의 정확도는 입력 데이터의 품질, 특히 기상 조건과 건물의 형상 및 운전 특성에 크게 의존한다.
건물의 열 및 에너지 성능을 분석하는 과정은 방대한 데이터를 처리해야 하며 매우 복잡하다. 실제 건물 데이터를 활용한 컴퓨터 시뮬레이션은 정확한 평가를 제공하지만, 전체 건물군에 대한 분석은 많은 시간과 자원이 소요된다. 이러한 한계를 해결하기 위한 대안으로, 실제 건물의 대표 샘플을 기반으로 통계적으로 도출된 표준 건물(reference building)을 개발하는 방법이 있다. 이 방법은 시뮬레이션 횟수를 대폭 줄이면서도 효율적인 에너지 분석을 가능하게 한다(Famuyibo et al., 2012).
미국 에너지부(DOE)는 건물 유형, 기후, 에너지 소비 수준에 따라 분류된 상업용 표준건물에 대한 광범위한 데이터베이스를 제공하고 있으며, 이는 열 및 에너지 성능 분석에 널리 활용되고 있다(Deru et al., 2025). 이러한 모델은 다양한 설계 시나리오에 대한 에너지 성능을 평가하고 비교할 수 있는 표준화된 프레임워크를 제공하기 때문에 건물 에너지 성능 분석에 자주 활용된다. 그러나 해당 표준 건물 모델은 미국의 건축 관행, 건축 유형, 운영 특성을 기반으로 개발되었기 때문에, 이를 다른 지역적 맥락에 직접 적용할 경우 시뮬레이션 결과에 상당한 오차가 발생할 수 있다.
이러한 한계점을 고려할 때, 지역별 건물 특성과 운영 특성을 보다 정확하게 반영할 수 있는 지역 맞춤형 표준 건물 모델의 개발이 필요하다. 이를 통해 보다 정확하고 의미 있는 에너지 성능 평가가 가능해질 것이다. 유럽에서는 TABULA 프로젝트(Loga et al., 2012)를 통해 주거용 건물 유형 분류 체계와 표준 건물 모델 개발을 위한 프레임워크가 구축되었다. 독일, 이탈리아, 프랑스, 스웨덴을 포함한 13개국이 참여하여, 자국의 건물 재고 특성에 맞춘 대표적인 건물 유형을 정의하였다(Ballarini et al., 2014).
여러 국가에서는 자국 실정에 맞춘 에너지 시뮬레이션용 표준 건물 모델을 개발하고자 다양한 연구를 수행해왔다. 예를 들어, Bhatnagar et al. (2019)은 인도에서 최근 10년간 건설된 230개의 업무 시설을 대상으로 상세한 데이터를 수집하여 저층 및 고층 업무 시설의 표준건물 모델을 개발하였다. 이들은 건물의 층수와 기후대를 기준으로 분류한 후, ANOVA, Kruskal–Wallis H 검정, 그리고 빈도 분포에 기반한 가중 평균과 같은 통계 기법을 활용하여 범주형 및 수치형 변수에 대한 대표값을 도출하였다. 또 다른 연구(Schaefer and Ghisi, 2016)에서는 브라질 플로리아노폴리스(Florianópolis) 지역을 대상으로, 저소득층 주택의 표준 건물 모델을 개발하였다. 이 연구에서는 120개 주택으로부터 현장에서 수집한 기하학적 데이터를 바탕으로 클러스터 분석을 수행하였으며, 클러스터 중심점에 가장 가까운 사례를 대표 모델로 선정하였다. 선정된 모델들은 에너지 시뮬레이션을 통해 검증되었으며, 그 적합성이 확인되었다.
한국에서도 표준 건물 모델 개발을 목적으로 한 연구가 수행된 바 있다. Kim et al. (2017)은 다양한 건물 유형에 대해 국가 단위의 에너지 소비량 데이터를 연면적 통계와 연계하여 대표 모델을 개발하고, 평균 에너지 사용지표에 맞추어 보정하였다. 통계적으로 평균적인 특성을 반영한 단일 존(single-zone) “가상 건물(virtual buildings)”을 기반으로 연구를 진행하였다. 연면적과 층수와 같은 매개변수는 국가 통계 평균을 기반으로 도출되었으며, 창면적비 및 장단변비와 같은 항목은 전문가의 판단에 따라 설정되었다. 각 건물 유형은 전국 평균을 반영한 단일 모델로 제시되었다.
과거 여러 연구에서 표준 건물 모델을 개발하기 위한 방법들이 제시된 바 있으나, 대한민국 업무 시설에 특화된 지역 기반의 데이터 표준(reference) 모델은 여전히 부족한 실정이다. 기존 연구들은 주로 국가 단위의 통계 평균이나 전문가의 판단에 따른 단일 대표 모델을 제시하는 방식이었으며, 이는 실제 건축물의 다양한 형태적 특성을 충분히 반영하지 못한다는 한계가 있었다. 현재까지 대한민국의 주요 도시 지역인 서울특별시 및 경기도를 대상으로 실측된 건축 형상 데이터를 클러스터링 기법을 활용하여 다수의 대표 업무 시설 유형을 정의한 연구는 수행되지 않았다.
이러한 연구적 공백을 보완하기 위해, 본 연구에서는 대한민국에서 가장 도시화가 진행된 지역인 서울특별시와 경기도의 모든 업무용 건물을 이용하여 국내 업무용 건물의 표본 건물 에너지 모델을 개발하고자 한다. 이를 위해 국가 건축물 대장으로부터 확보한 정량적 형상 데이터를 기반으로, 건축물의 물리적 특성에 따라 계층적 클러스터링(hierarchical clustering) 기법을 적용하여 건물을 여러 유형으로 분류하였다. 각 그룹에 대해 다중 존(multi-zone) 기반의 상세 표준 건물 모델을 구축함으로써, 보다 실제에 가까운 형태적 다양성과 지역 특성을 반영한 에너지 성능 시뮬레이션 기반을 마련하였다.
측정개요
본 연구는 (i) 표준 건물 모델 생성을 위한 대표 건축물의 특성 파악, (ii) 도출된 특성을 기반으로 한 EnergyPlus 모델 구축의 두 가지 단계로 구성되었다:
기준 건물 파라미터 식별
한국의 일반적인 업무 시설 특성을 반영한 표준 건물 모델을 개발하기 위해, 본 연구에서는 시뮬레이션 입력 항목들을 (i) 건물 형상 구성, (ii) 외피 구성, (iii) 내부 발열 조건, (iv) 운전 스케줄로 구분하여 정의하고 설정하였다.
건물 기하학적 형상 구성
표준 업무 시설의 일반적인 형상을 결정하기 위해, 본 연구에서는 데이터 수집, 데이터 정제, 탐색적 분석, 군집화의 절차로 구성된 체계적인 과정을 수행하였다(Figure 1). 먼저, 서울특별시와 경기도 지역의 업무 시설에 대한 건물 및 공간 데이터를 수집하였다. 수집된 데이터는 전반적인 건물 특성과 경향을 파악하기 위해 정제 및 분석되었으며, 이후 유사한 형상의 건물들을 군집화하여 대표적인 기하학적 특성을 식별하였다. 이러한 과정을 통해 해당 지역의 전형적인 업무 시설을 반영하는 대표 형상을 도출할 수 있었다.
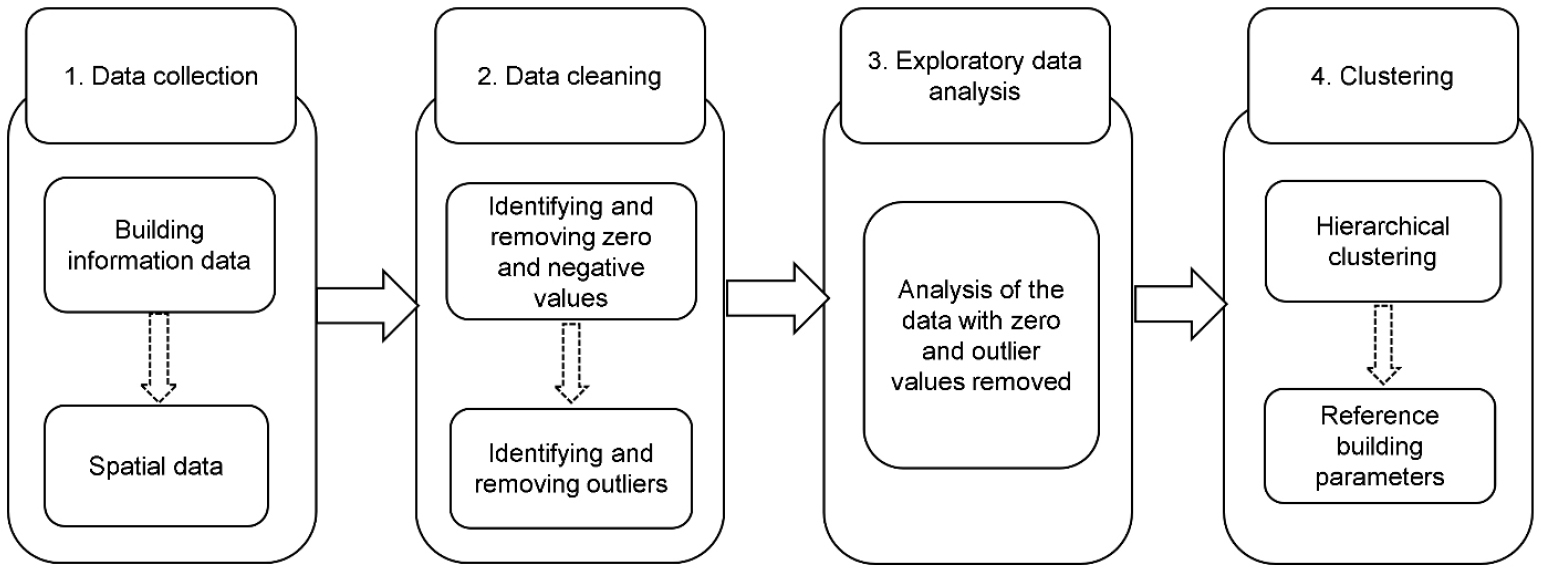
(1) 데이터 수집
데이터 수집 과정은 서울특별시와 경기도에 위치한 기존 업무 시설에 대한 건축 정보 데이터와 공간 데이터를 통합하는 방식으로 이루어졌다. 활용한 주요 데이터의 출처는 (i) 국가 건축물 대장 데이터베이스와 (ii) 공간 데이터셋의 두 가지이다. 건축 정보는 대한민국 전역의 건축물에 대한 광범위한 기록을 제공하는 건축물대장 오픈 데이터 포털(Ministry of Land I and T. Building Open Data Portal, 2022)을 통해 수집되었다. 이 데이터셋에는 연면적, 대지 위치, 건물 높이, 지상 및 지하 층수, 사용 승인일 등 핵심적인 행정 및 구조적 속성이 포함되어 있다. 총 1,912,969건의 건물 데이터가 수집되었으며, 이 중 16,529개 건물이 업무 시설로 분류되어 추가 분석을 위해 선정되었다.
공간 데이터는 V-WORLD 플랫폼(MOLIT, 2021), 을 통해 수집되었다. 해당 데이터에는 건물의 지리적 외형을 나타내는 SHP(쉐이프파일) 형식의 도면이 포함되어 있으며, 각 건물의 용도 분류 및 지리 좌표(X, Y) 정보가 함께 제공되었다. 통합된 데이터셋을 구축하기 위해, 건축물 정보와 공간 데이터는 각 건물에 부여된 고유 식별자(Primary Key, PK)를 기반으로 매칭되었다. 이 매칭 과정은 기하학적 정보와 속성 정보를 일관되게 연결하여 후속 분석이 가능하도록 하는 데 목적이 있다.
SHP 파일 외에도, 건물 높이 데이터의 정확성과 완성도를 향상시키기 위해 해상도 1 m의 디지털 표면 모델(DSM)과 디지털 지형 모델(DEM) 자료가 활용되었다. DEM은 지표면에 존재하는 건물, 식생 등의 요소를 제외한 순수한 지형 표면을 나타내며, DSM은 건물, 식물, 기타 구조물을 포함한 실제 지표의 높이를 반영한다. DSM과 DEM은 건축물 대장에 기록된 건물 높이 값을 검증하고, 누락된 높이 정보를 보완하는 데 주로 사용되었다. 건물 높이는 DSM 값에서 DEM 값을 차감하여 계산되었으며, 그 결과는 건축물 대장 정보와 교차 검토되어 데이터의 신뢰도를 높였다.
추가적인 기하학적 처리는 QGIS를 활용하여 각 건물의 장단변비(W/D 비율)를 산출하는 방식으로 수행되었다. 유효한 건물 길이는 SHP 파일을 기반으로 측정되었으며, 이를 연면적 정보를 통해 보정하였다. 이후 해당 길이에 기반하여 건물 폭을 추정하였고, 이를 바탕으로 장단변비를 계산하였다. 이 지표는 이후 클러스터링 분석에서 주요 기하학적 변수 중 하나로 활용되었다.
이와 같은 체계적인 다중 소스 기반의 데이터 수집 과정을 통해, 대표적인 업무 시설 건물 형상을 정의하는 데 필요한 물리적 및 기능적 속성을 모두 포함하는 포괄적이고 일관된 데이터셋을 구축하였다.
(2) 데이터 정제 및 탐색적 데이터 분석
데이터셋의 수집 이후, 분석의 신뢰성과 일관성을 확보하기 위한 체계적인 데이터 정제 과정이 수행되었다. 첫 번째 단계에서는 대지면적, 건축면적, 연면적, 용적률산정연면적, 건물 높이, 지상층수 등 주요 변수에 0 또는 음수 값이 포함된 레코드를 식별하고 제거하였다. 이러한 값들은 누락되었거나 잘못 기록된 항목으로 간주되어 분석 결과를 왜곡시킬 수 있으므로 제외되었다.
0 또는 음수 값을 제거한 이후에도, 일부 건물에는 비정상적으로 작거나 비현실적인 값이 포함되어 있었다. 이를 해결하기 위해 사전에 정의된 기준에 따라 추가적인 필터링을 수행하였다. 다음 조건 중 하나라도 충족하는 레코드는 분석에서 제외되었다. (i) 대지_면적 10 ㎡ 미만, (ii) 건축_면적 5 ㎡ 미만, (iii) 연면적 10 ㎡ 미만, (iv) 용적률산정연면적 10 ㎡제로 및 이상치 값 제거 미만, (v) 건물 높이 3 m 미만.
이러한 기준은 입력 오류로 판단되는 구조물을 제거하기 위해 설정된 것으로, 일반적인 업무시설의 특성을 반영하지 않는 사례들을 걸러내기 위해 적용되었다. 하한값에 대한 필터링 외에도, 상한값에 해당할 수 있는 이상치들은 산점도 분석을 통해 검토되었다. 값이 지나치게 큰 건물들은 시각적으로 검토되었으며, 전체 데이터 분포와 명백하게 불일치하는 경우에 한해 분석에서 제외되었다.
이러한 2단계 데이터 정제 과정을 통해 남은 데이터셋은 정확성과 일관성을 확보하였으며, 실제 업무시설을 대표할 수 있는 특성을 반영하게 되었다. 이를 바탕으로 이후 분석 단계에 활용할 수 있는 견고한 기반이 마련되었다.
(3) 클러스터링
본 연구에서는 건물의 구조적 속성을 기반으로 유사한 기하학적 특성을 가진 건물들을 그룹화하기 위해 계층적 군집화(hierarchical clustering) 기법을 적용하였다. 이 방법은 유사도의 수준에 따라 데이터를 병합하거나 분할하면서 계층적인 군집 구조를 형성한다. 계층적 군집화에는 크게 두 가지 방식이 있으며, 상향식(agglomerative) 방식과 하향식(divisive) 방식이 있다. 상향식 방식은 각 데이터를 개별 군집으로 시작한 뒤, 가장 유사한 군집을 반복적으로 병합하여 최종적으로 하나의 군집으로 통합한다. 반면에, 하향식 방식은 전체 데이터를 하나의 군집으로 시작해 점차 유사성이 낮은 하위 군집으로 분할해 나가는 방식이다. 본 연구에서는 상향식 방식(agglomerative method)을 채택하였다.
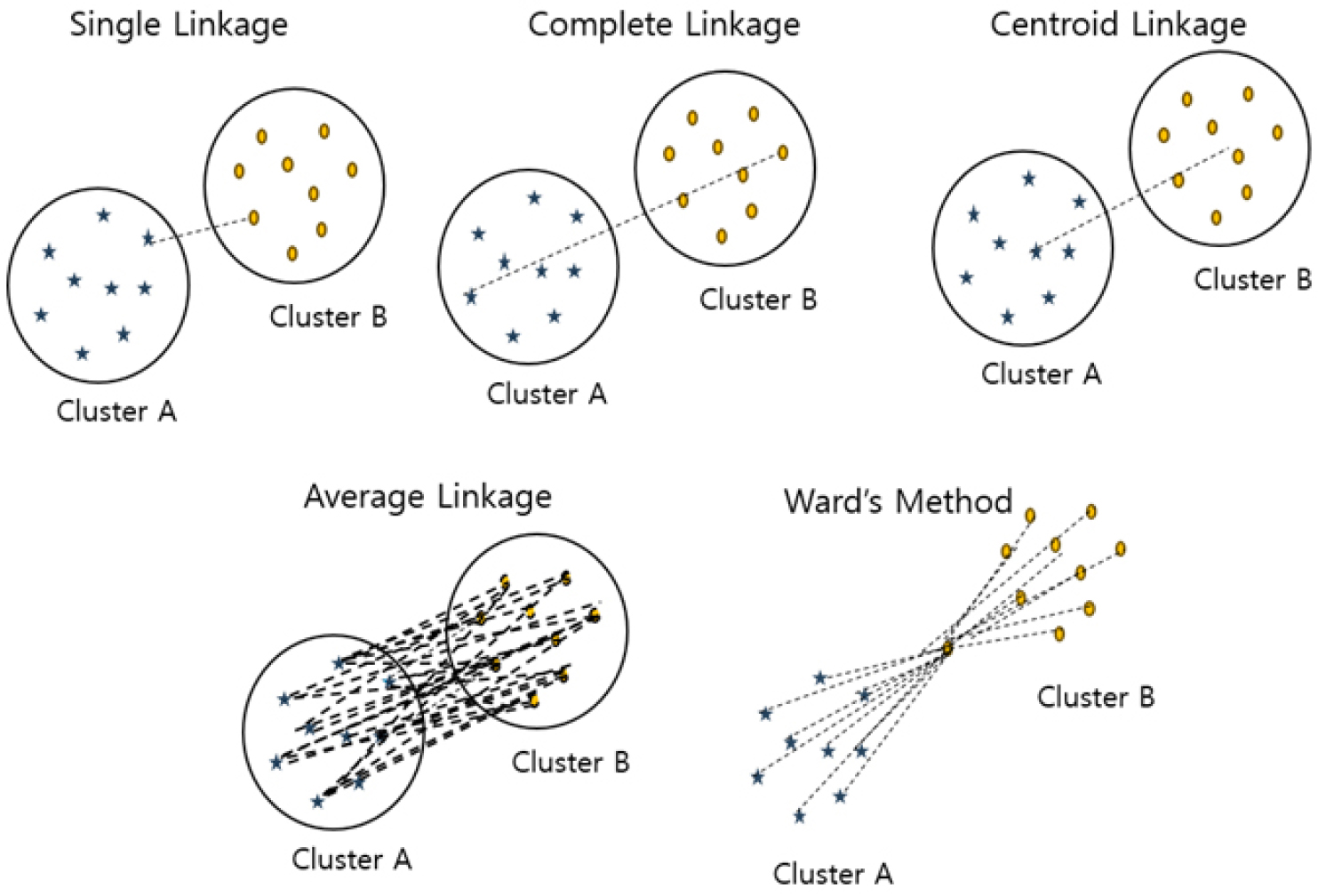
군집 간 거리를 정의하는 방법으로는 여러 가지 연결(linkage) 기법이 있으며, 그 대표적인 방식으로는 다음과 같은 다섯 가지가 있다: (i) 단일 연결법(single linkage), (ii) 완전 연결법(complete linkage), (iii) 중심 연결법(centroid linkage), (iv) 워드 방법(Ward’s method), (v) 평균 연결법(average linkage)이다. Figure 2 은 각 연결 방법(linkage)의 그래픽 표현을 제공합니다.
단일 연결법은 서로 다른 두 군집에 속한 모든 데이터 쌍 중에서 가장 가까운 두 점 간의 거리를 기준으로 군집을 병합한다. 반면, 완전 연결법은 가장 먼 두 점 간의 거리를 사용하여 군집을 병합하므로 보다 조밀하고 균일한 군집을 형성하게 된다. 중심 연결법은 각 군집의 중심점(centroid) 간의 거리를 기준으로 군집 간 유사도를 판단한다. 워드 방법은 두 군집을 병합하였을 때 군집 내 분산(또는 제곱합, SSE: sum of squared errors)의 증가량을 최소화하는 방식으로, 군집 내의 내부 변동성이 가장 작도록 군집을 구성하는 데 효과적이다. 마지막으로 평균 연결법은 두 군집에 속한 모든 데이터 쌍 간 거리의 평균값을 기준으로 군집 간 거리를 정의한다.
본 연구에서는 군집 내의 내부 변동성을 최소화할 수 있는 워드 방법(Ward’s method)을 적용하였다.
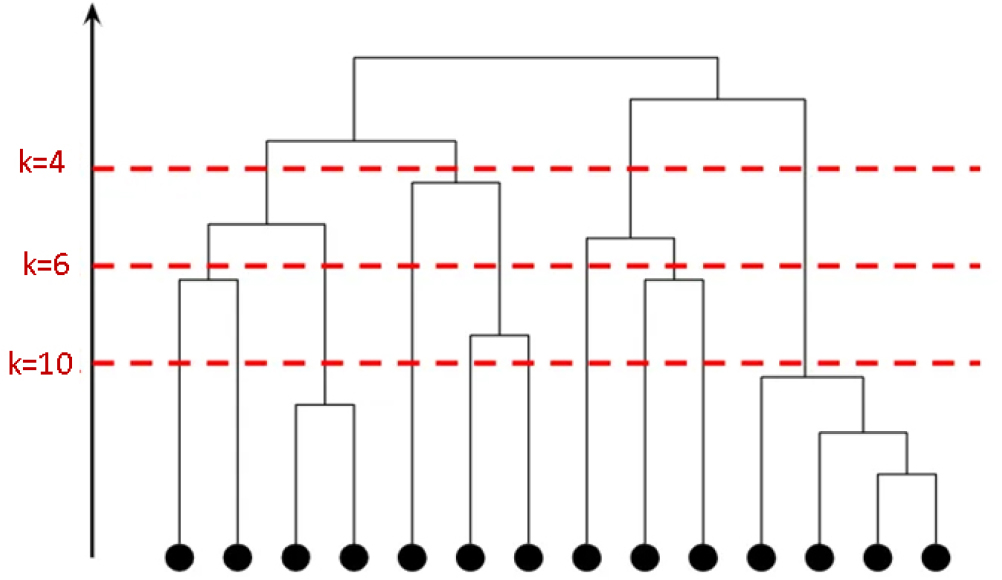
계층적 군집 분석을 수행한 후에는 덴드로그램(dendrogram)을 생성하여 군집 간의 계층적 구조를 시각화한다. 덴드로그램은 개별 데이터들이 서로 얼마나 유사한지를 기준으로 단계적으로 군집화되는 과정을 나무 형태로 보여주는 도식이다. 수직축은 군집 간의 거리 또는 비유사도(dissimilarity)를 나타내며, 수평선으로 절단(cut)을 하면 해당 지점에서의 군집 개수를 결정할 수 있다. 이러한 시각화는 데이터의 군집 구조를 직관적으로 파악하고 최적의 군집 수를 결정하는 데 도움을 준다. Figure 3은 덴드로그램(dendrogram)의 개략적인 구조를 보여줍니다.
최적의 군집 개수를 결정하기 위해 실루엣 분석(silhouette analysis)을 수행하였다. 실루엣 계수(silhouette coefficient)는 각 데이터 지점이 속한 군집 내에서 얼마나 잘 맞는지를 평가하고, 동시에 다른 군집과의 구분 정도를 측정하는 지표이다. 이는 해당 지점과 같은 군집 내 다른 포인트들과의 평균 거리 (aᵢ) 와, 가장 가까운 다른 군집의 포인트들과의 평균 거리 (bᵢ) 를 이용해 계산된다(Figure 4). 실루엣 계수 sᵢ 는 다음과 같이 정의된다:
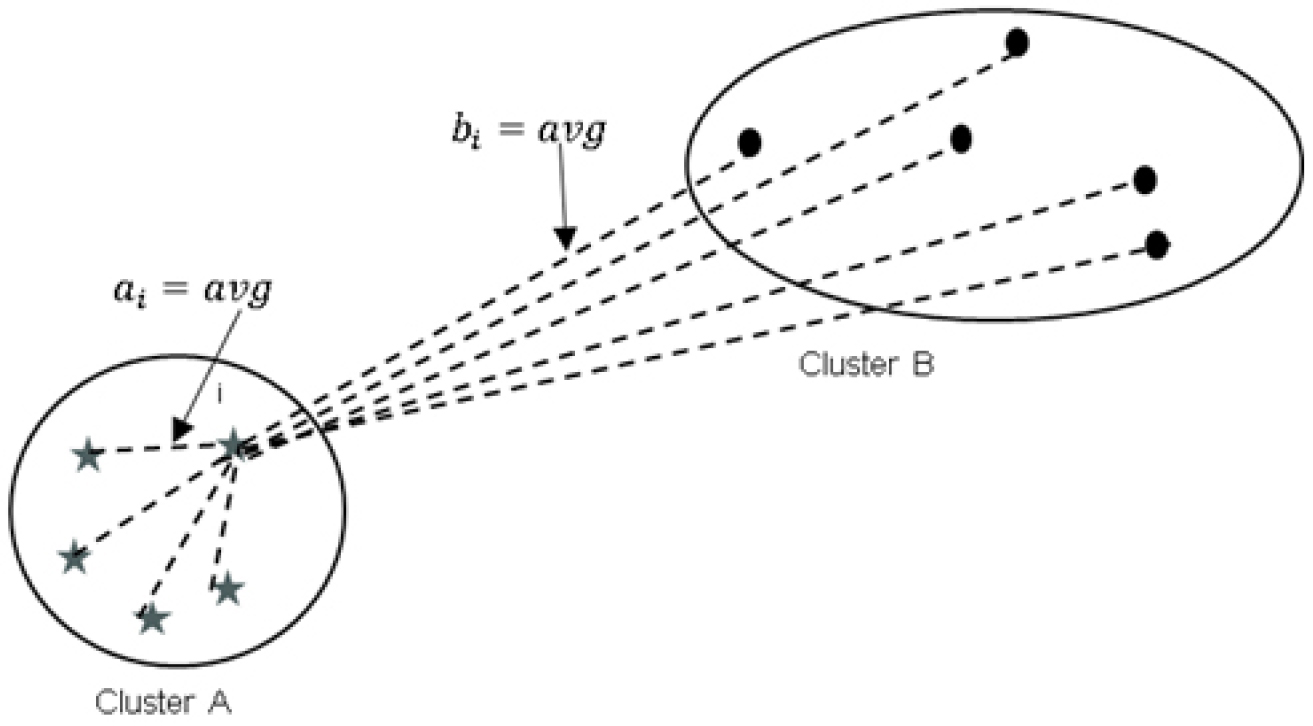
이 계수는 -1에서 1 사이의 값을 가지며, 1에 가까울수록 해당 지점이 적절한 군집에 잘 속해 있다는 것을 의미한다.
군집화가 완료된 후, 도출된 군집들은 장단변비 데이터셋과 매칭되어 각 군집에 속한 건물에 해당 값이 부여되었다. 장단변비 정보를 군집 특성에 통합함으로써, 각 대표 업무 시설 유형을 정의하는 기하학적 특성에 대한 보다 포괄적인 분석을 가능하게 하였다.
(4) 창면적비 산정
클러스터링 결과와 주요 기하학적 파라미터가 도출된 후, 창면적비(WWR, Window-to- Wall Ratio)를 산정하였다. 이를 위해, 전체 건물 중에서 각 클러스터의 평균 기하학적 특성과 가장 유사한 건물을 선정하였다. 클러스터별 평균값에 가장 근접한 건물을 식별하기 위해 Python 스크립트를 작성하였으며, 각 건물은 고유한 PK 번호를 통해 후보로 선정되었다. 이후 해당 건물의 실제 주소를 확인하고, 스트리트 뷰 및 위성 영상을 활용한 시각적 검토를 통해 동·서·남·북 방향별 창면적과 벽면적을 수동으로 측정하였다. 이러한 측정을 바탕으로 각 클러스터의 방향별 창면적비가 산출되었다.
(5) 존 구성
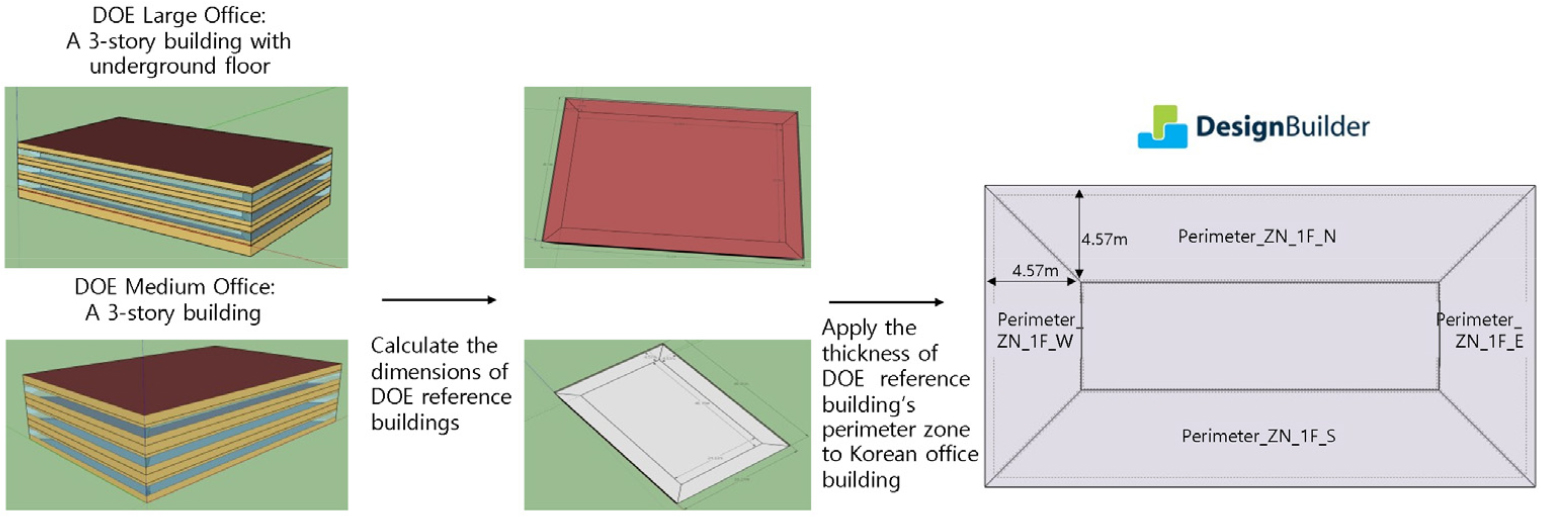
본 연구에서의 존 구성은 미국 에너지부(DOE)의 상업용 표준건물 모델, 특히 Medium Office 및 Large Office의 EnergyPlus 템플릿을 참조하여 설정되었다. 이들 모델은 에너지 성능 시뮬레이션에서 널리 사용되는 표준화된 구조적 및 열적 존 구성 구조를 제공한다.
DOE Medium Office 모델의 수직 존 구성 방식을 따르며, 각 층은 두 개의 수직적으로 적층된 존으로 구분된다: (i) 재실구역(높이 2.44 m)은 재실자 및 내부 발열이 발생하는 주요 냉·난방 공간을 의미하며, (ii) 플레넘(높이 1.2 m)은 주로 리턴 공기 경로와 덕트, 단위공조기 등 공기 분배 설비가 배치되는 천장의 빈 공간을 나타낸다.
해당 존 구성 방식은 층간 높이(바닥에서 바닥까지 높이)로 총 3.64 m를 가지며, 이는 모든 층에 균일하게 적용되었다. 또한, 외곽 존의 깊이는 DOE Medium Office 및 Large Office 참조 모델에서 정의된 수평 존 구성을 기준으로 4.57 m로 설정되었으며, 이는 외벽에 인접한 외곽 냉·난방 존을 정의하는 데 사용되었다. Figure 5은 오피스 건물의 존 구성(zone configuration)을 보여줍니다.
외피 구성
건물 외피의 재료 구성과 열 물성치를 결정하기 위한 문헌 조사가 수행되었다. Google Scholar, Scopus, DBpia 등의 학술 검색 플랫폼을 활용하여 SCI 및 KCI에 등재된 국내 건물 관련 연구들을 수집하였다. 수집된 문헌 중 벽체 및 지붕 구성에 대한 구체적인 정보—재료 유형, 층 두께, 열전도율, 밀도, 비열 등 열 물성치—를 제공하는 논문들을 선별하였다. KCI 논문의 경우 최근 5년 동안 대한건축학회, 한국건축친환경설비학회, 한국생활환경학회, 대한설비공학회, 한국태양에너지학회에서 게재된 논문을 조사하였으며, 국내 건축물의 에너지 시뮬레이션과 관련된 논문 30편 중 재료 구성이 제시된 논문 7편을 활용하여 정보를 도출하였다. SCI 논문에서는 세부 열적 물성치 정보가 포함된 논문을 International Journal of Energy and Environmental Engineering, Architectural Research, Applied Thermal Engineering 저널에서 게재된 논문 3편을 통해 자료를 도출하였다. 이를 토대로, 업무 시설에 적합한 대표적인 외피 구성을 정의하였으며, 이를 EnergyPlus 시뮬레이션에 적용하였다. Figure 6은 문헌 검토를 기반으로 EnergyPlus 모델링에 사용할 건축 자재를 선택하는 워크플로(workflow)를 요약한 것이다.
건물 외피의 열성능은 국내의 「건축물 에너지 절약설계기준」에 따라 설정되었다. 해당 기준은 건축 연도에 따라 여러 차례 개정되었으며, 적용 시기는 1980년 이전, 1980–1984년, 1984–1987년, 1987–2001년, 2001–2008년, 2008–2010년, 2010–2012년, 2012–2015년, 2015–2018년, 그리고 2018년 이후로 구분된다. 각 시기별로 요구되는 열관류율(U-value) 기준이 상이하며, 이에 따라 외벽 구성의 단열재 두께와 관련 층의 물성이 조정되었다. 창호의 경우, 태양열취득계수(SHGC) 및 가시광선 투과율과 같은 유리 성능 값이 각 기준에 따라 설정되었으며, 적용된 값들은 서울 및 경기 지역의 기후 조건을 반영하였다. 본 연구에서 활용한 외피 구성 및 년도별 열성능 수치는 부속 표Table 1에 정리하였다.
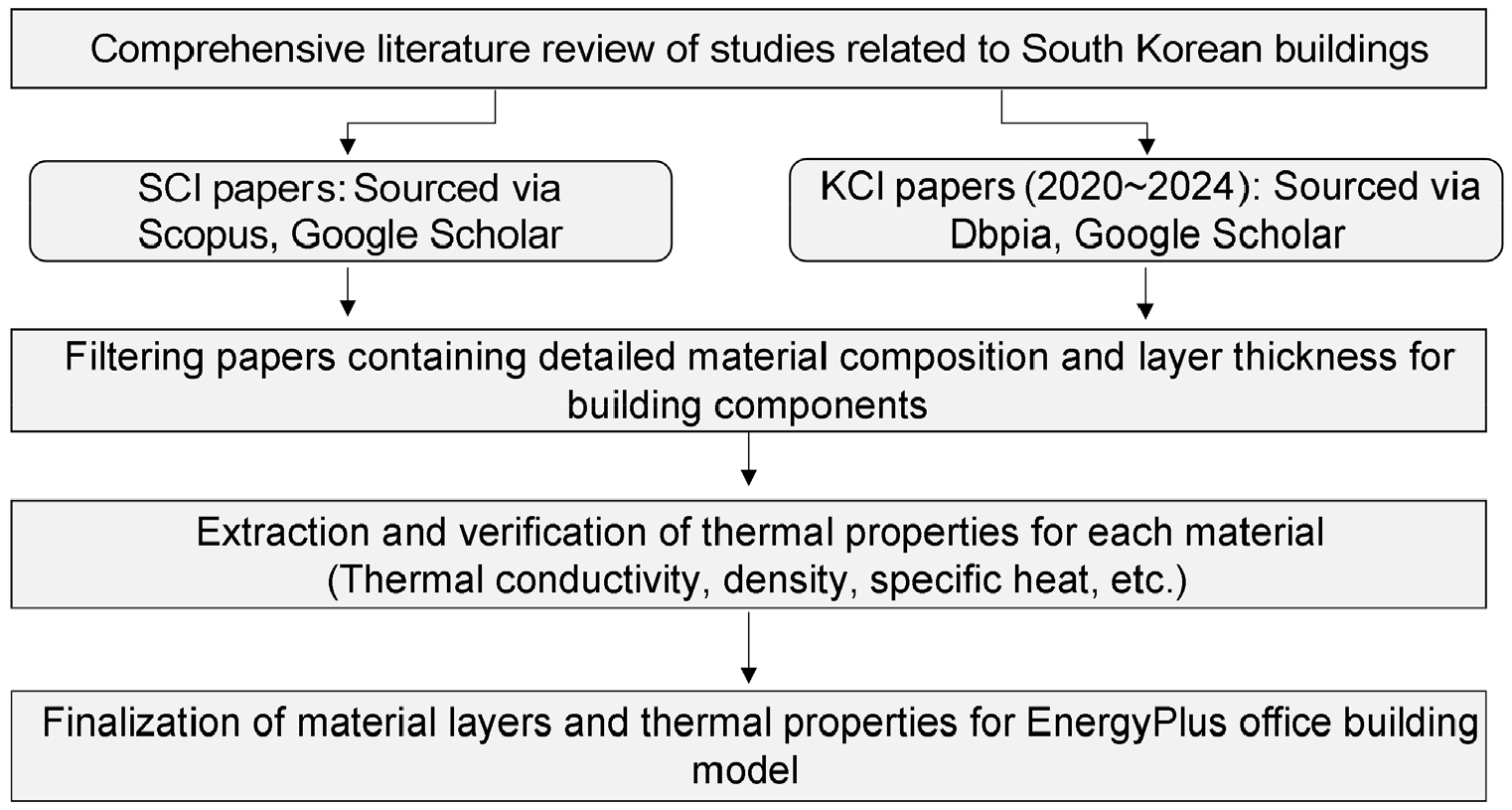
Table 1.
Summary of Thermal Transmittance and Envelope Material Properties Across Construction Periods for Seoul and Gyeonggi
내부 발열량
내부 발열량(Internal heat gains)은 재실자, 조명, 그리고 기기 사용으로 인해 건물 내부에서 발생하는 열을 의미한다. 이러한 발열은 건물의 열 부하와 에너지 수요에 직접적인 영향을 미치며, 건물 에너지 시뮬레이션에서 일반적으로 단위 면적당 전력(W/m2)으로 표현된다.
총 내부 발열량은 세 가지 요소로 구성된다. 첫째, 재실자 발열은 공간 내 개인의 활동 수준, 재실 인원수, 그리고 스케줄에 따라 달라지는 대사 활동으로부터 발생하는 열을 의미한다. 둘째, 조명 발열은 인공 조명에서 방출되는 열로, 조명 밀도와 작동 시간에 따라 달라진다. 셋째, 기기 발열은 컴퓨터, 프린터 등 전자기기의 사용에서 발생하며, 기기의 전력 밀도와 사용 스케줄에 의해 영향을 받는다.
표준 업무 시설의 내부 발열량 값을 결정하기 위해 다양한 문헌에서 자료를 수집하였다. 참고 문헌에는 ECO2-2021 공학 매뉴얼(KIAEBS, 2021), 미국 DOE의 참조 건물 파일, 대형 개방형 사무공간을 위한 DIN V 18599-10:2018(DIN V 18599-10, 2018), SBEM 2017 (Generic Office Area)(BRE, 2017), ISO 17772-1:2017(ISO 17772-1, 2017) 등이 포함된다. 재실 밀도와 대사 발열량을 포함한 재실자 관련 수치는 ECO2-2021(KIAEBS, 2021) ASHRAE Fundamentals(ASHRAE, 2021), 를 바탕으로 선정하였으며, 이는 국내 업무 시설에 적합한 널리 인정된 기준을 제공하기 때문이다. 조명 및 기기 발열 수치는 각 문헌의 값을 비교 분석하여 도출하였으며, 본 연구에서 검토한 모든 기준값은 부속 표 (Tables 2, 3, 4, 5)에 정리하였다.
Table 2.
Reference Occupant Density Values for Internal Heat Gain Calculation in Office Buildings
Table 3.
Reference Occupant Sensible Heat Gain Values for Office Buildings from International and Domestic Standards
Table 4.
Reference Equipment Heat Gain for Office Buildings According to International and Domestic Standards
Table 5.
Reference Lighting Heat Gains for Office Buildings According to Various Standards
| Value | DOE | ECO2-2021 | PNNL | ASHRAE 90.1 |
|
Lighting heat gain (W/m2) | 10.76 | - | 11.8 | 10.76 |
운전 스케줄
건물 에너지 모델링에서 스케줄은 시간의 흐름에 따라 내부 발열과 시스템 운전이 어떻게 변화하는지를 정의하며, 이는 실제 건물 사용 패턴을 반영한다. 이러한 스케줄은 재실자 존재 여부, 조명 및 기기 사용, HVAC 운전, 온도 설정값, 침기 등의 변화를 시간별, 일별, 주간, 연간 단위로 고려한다.
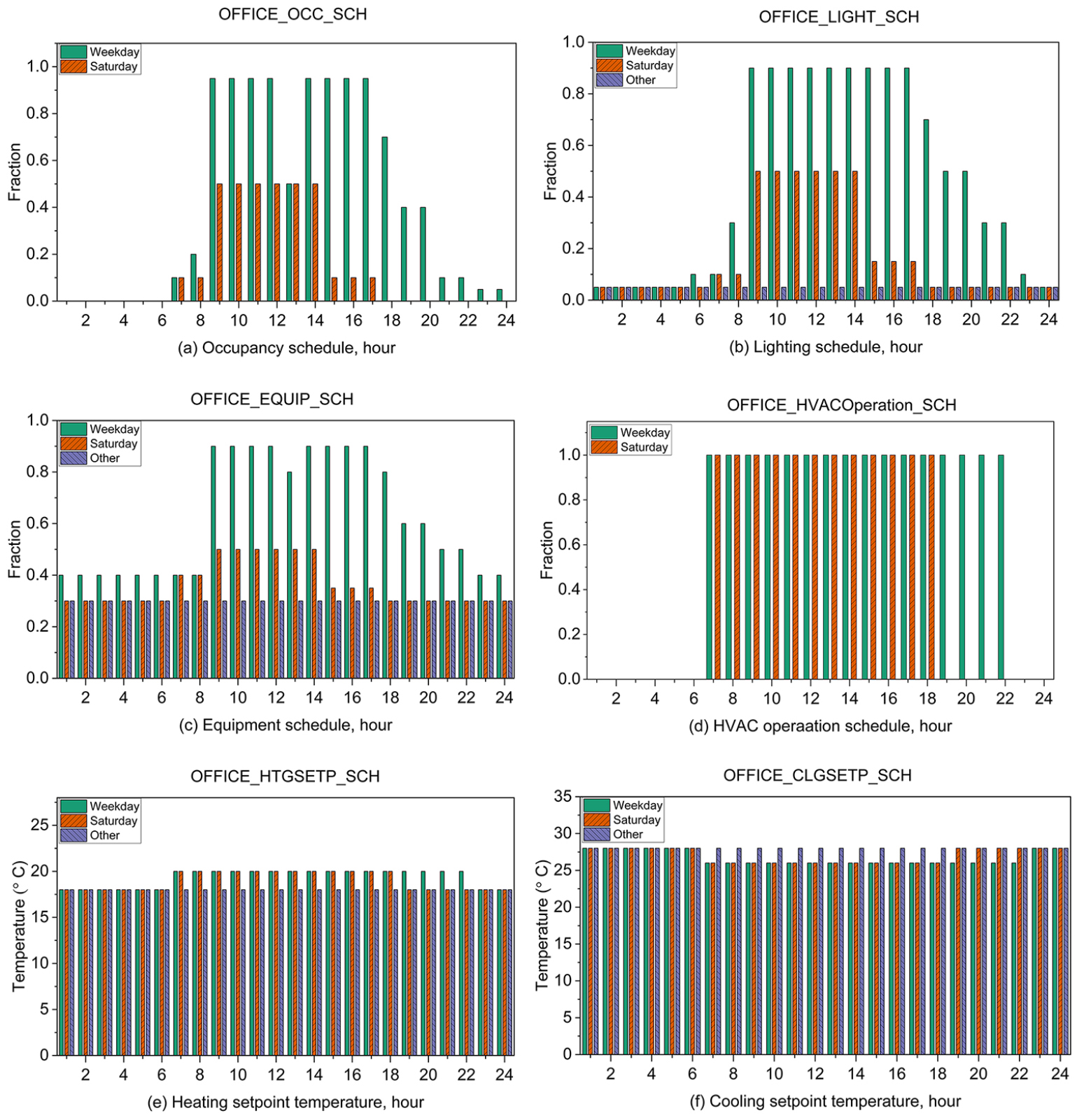
본 연구에서는 재실률, 활동 수준, 착의율, 작업 효율 등 재실자 관련 스케줄, 조명 및 기기 사용에 따른 내부 발열 스케줄, 난방 및 냉방 설정온도를 포함한 HVAC 운전 스케줄, 그리고 침기 제어 스케줄을 고려하였다.
한국 업무용 건물에 특화된 공개 스케줄 데이터가 부족하여, 본 연구에서는 모든 스케줄을 미국 에너지부(Department of Energy, DOE)의 상업용 참조 건물 모델에서 도출하였으며, DesignBuilder의 Activity, Lighting, Equipment, HVAC 설정 등의 모듈을 통해 적용하였다. 난방 및 냉방의 설정 온도는 각각 20℃와 26℃로 설정되었으며, 시뮬레이션에 사용된 대표적인 스케줄 프로파일은 Figure 7에 제시되어 있다.
EnergyPlus 모델 생성
EnergyPlus 모델은 건물 형상, 외피 구성, 내부 발열, 스케줄, HVAC 시스템 구성 및 침기 관련 매개변수에 대한 수집 데이터를 기반으로 개발되었다. 초기 건물 모델은 EnergyPlus 시뮬레이션 엔진의 그래픽 사용자 인터페이스(GUI) 역할을 하는 DesignBuilder를 활용하여 생성되었으며, 수집된 표준화된 데이터를 바탕으로 공간 구획, 자재층 구성, 실내 조건, HVAC 템플릿 등 제작에 필요한 모든 필수 입력 항목을 정의하였다. 모델링이 완료된 후, DesignBuilder에서 IDF (Input Data File) 형식으로 파일을 추출하여 EnergyPlus 시뮬레이션을 수행하였으며, 필요 시 사례별 가정이나 국내 규제 요구 사항과의 일관성을 확보하기 위해 IDF 파일 내에서 추가 수정을 진행하였다.
결과 및 토의
군집 분석을 통한 참조 건물 기하학적 형상 결정
탐색적 데이터 분석
본 연구에서 사용된 데이터셋은 방법론 절에서 설명한 바와 같이, 0값 및 극단값을 제거한 후 총 12,317개의 업무시설 데이터를 포함하였다. 분석에 사용된 여섯 가지 주요 형상 변수인 대지면적, 건축면적, 연면적, 용적률산정연면적, 건물 높이, 그리고 지상층수에 대한 기술통계량을 표(Table 6)에 요약하였다.
Table 6.
Summary Statistics of Key Geometric Features in the Cleaned Office Building Dataset Used for Clustering Analysis
데이터 정제 후, 대지면적은 11.03 m2에서 415,141 m2 사이의 범위를 보였으며, 중앙값은 735.8 m2, 표준편차는 8,378.45 m2였다. 건축면적은 최소 7.36 m2, 최대 38,162.99 m2로 나타났고, 중앙값은 361.2 m2, 표준편차는 1,546.38 m2였다. 연면적의 경우 10.18 m2에서 240,695.84 m2 범위였으며, 중앙값은 2,739.81 m2, 표준편차는 16,113.40 m2로 나타났다. 용적률산정연면적은 10.18 m2에서 162,869.11 m2까지 분포하였고, 중앙값은 2,128.8 m2, 표준편차는 10,315.65 m2였다. 건물 높이는 3 m에서 249.58 m까지 분포하며, 중앙값은 29.3 m였다. 지상층수는 1층에서 60층까지의 분포를 보였고, 중앙값은 8층이었다.
기술통계 분석 결과, 서울 및 경기도의 업무시설 건물군은 상당한 이질성을 나타내는 것으로 확인되었다. 변수별로 나타난 넓은 값의 범위와 큰 표준편차는 건물의 규모와 형태가 다양함을 보여주며, 반면 중앙값이 비교적 일정하게 유지된다는 점은 데이터의 중심 경향이 안정적이라는 것을 시사한다. 이는 데이터 정제 과정이 극단적인 이상치를 효과적으로 제거하면서도 전체 분포의 구조를 왜곡하지 않았음을 의미한다. 따라서 정제된 데이터셋은 대표 참조 건물 유형을 도출하기 위한 군집 분석의 견고한 기반을 제공한다.
이러한 경향을 보다 명확하게 시각화하기 위해, 각 변수에 대한 히스토그램을 생성하여 Figure 8에 제시하였다. 이 히스토그램들은 정제된 최종 데이터셋에서 주요 형태적 변수들의 분포 형태와 빈도를 보여준다.
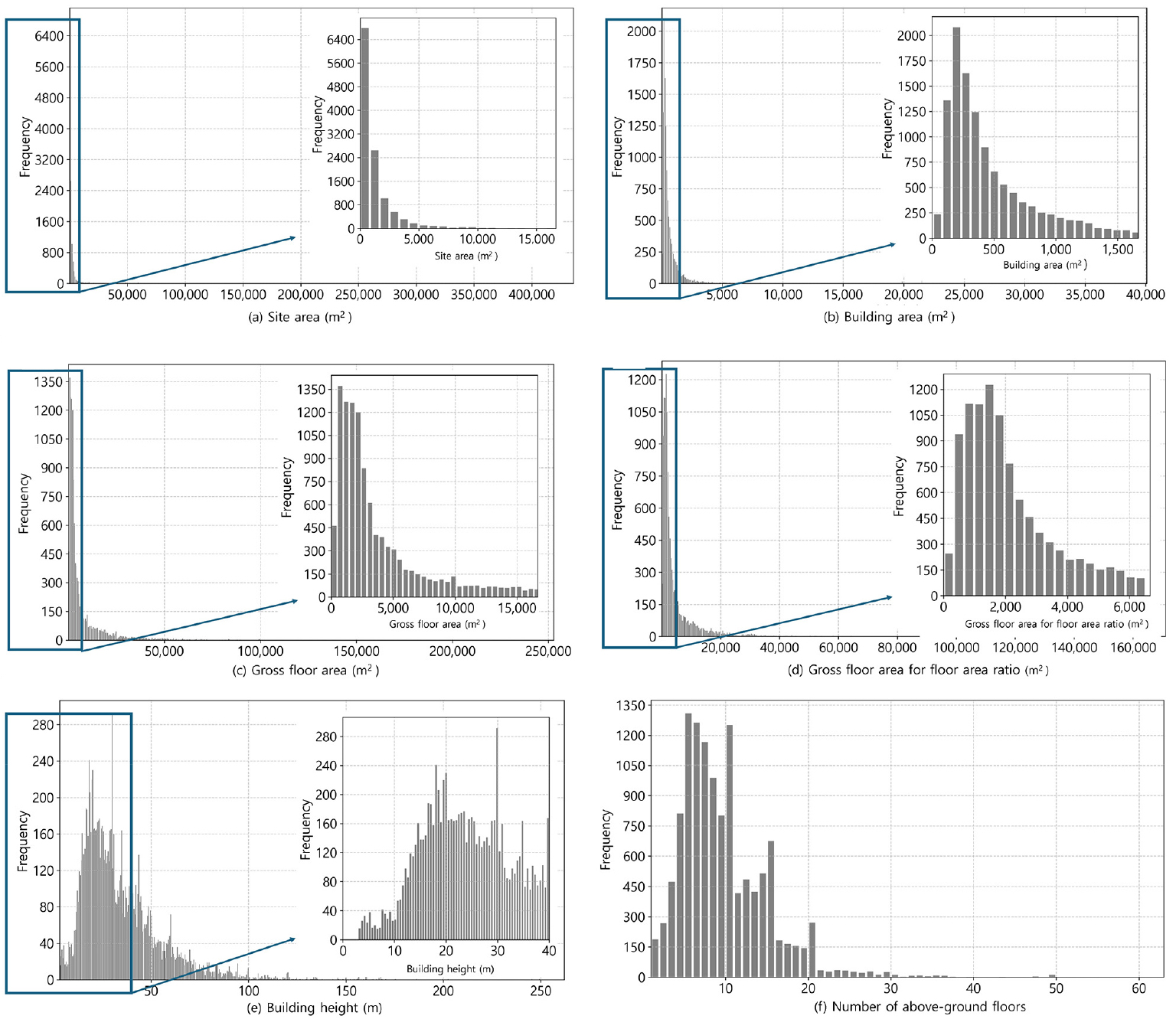
히스토그램 분석 결과, 대부분의 변수에서 건물들이 하위 범위에 집중되어 있는 것으로 나타났다. 예를 들어, 대지면적, 건축면적, 연면적, 용적률산정연면적은 우측으로 긴 꼬리 분포(right-skewed distribution)를 보이며, 대부분의 건물이 소형 또는 중형 규모인 반면 일부 건물은 매우 큰 면적을 차지하고 있음을 시사한다. 건물 높이는 오른쪽으로 긴 꼬리 분포를 보이며, 약 30미터 구간에서 가장 높은 빈도를 나타내어 데이터셋 내 대부분의 건물이 중층임을 시사합니다. 지상층수 분포를 보면 5층 건물이 가장 일반적으로 나타나며, 그 뒤를 이어 6층과 10층에서 뚜렷한 피크가 관찰됩니다. 이러한 분석 결과는 데이터셋 내에 존재하는 형태적 특성의 다양성을 뒷받침하며, 대표적인 건물 유형을 도출하기 위해 군집화 기반의 접근 방식이 필요함을 시사한다.
군집화 결과
본 연구에서는 건물의 형태적 특성에 따라 군집화를 수행하여 유사한 특성을 가진 건물들을 분류하였다. 최적의 군집 수를 결정하기 위해 군집 별 실루엣 계수 (silhouette coefficient)를 평가 지표로 사용하여 표 (Table 7)에 요약하였다. 표에 나타난 바와 같이 군집 수가 2일 때 실루엣 계수가 0.8174로 가장 높게 나타났다. 이는 본 데이터셋에서 두 개의 군집으로 분류하는 것이 가장 신뢰할 수 있는 건물 유형 구분임을 의미한다.
Table 7.
Silhouette coefficient summary
그에 상응하는 덴드로그램은 Figure 9에 제시되어 있으며, 데이터의 계층적 구조에 따라 두 개의 주요 군집이 식별될 수 있음을 확인할 수 있다.
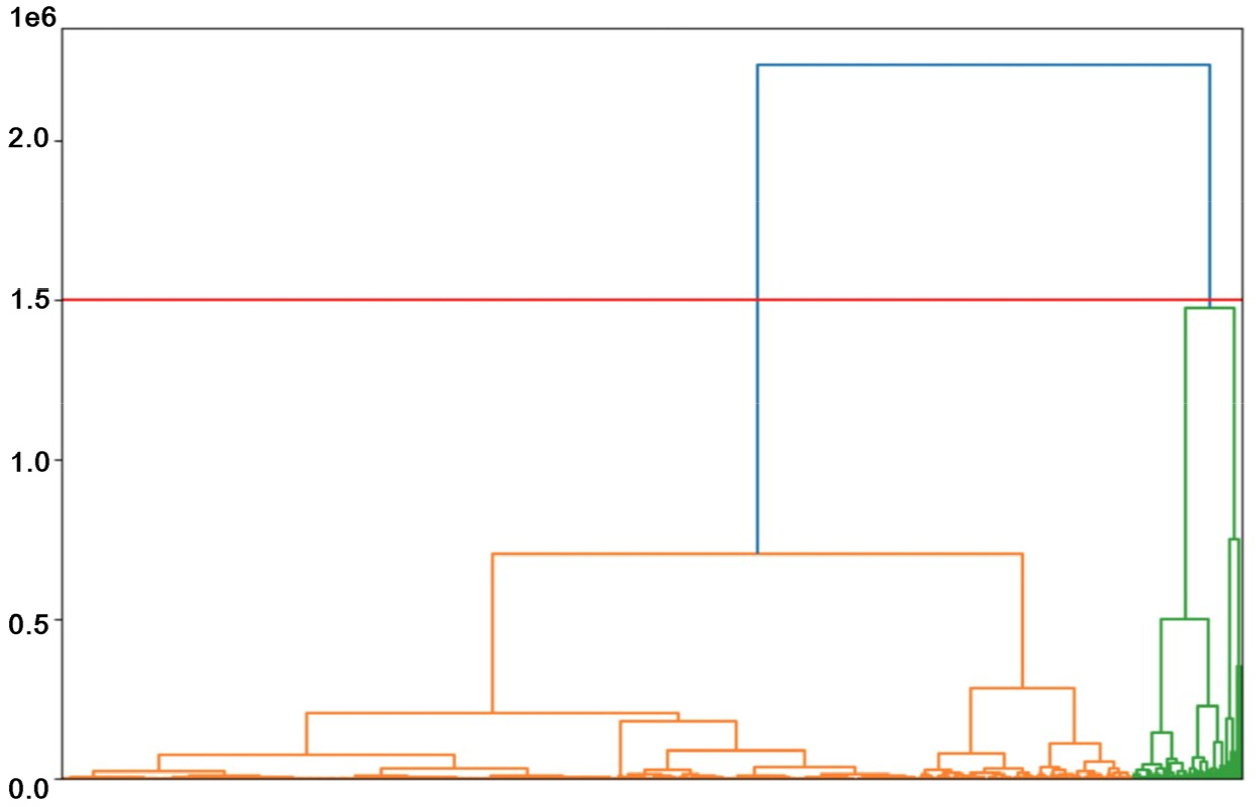
각 클러스터의 평균 기하학적 특성은 Table 8에 요약되어 있다. 클러스터 1에는 건축면적 552.92 m2, 연면적 4,091.85 m2, 건물 높이 28.38 m, 지상층수 8층의 건물들이 포함된다. 반면 클러스터 2는 건축면적 2,611.95 m2, 연면적 45,522.63 m2, 건물 높이 72.39 m, 지상층수 18층으로 구성된 더 크고 높은 건물들을 나타낸다. 이에 따른 평균 장단변비는 클러스터 1이 1.83, 클러스터 2가 2.05로 나타났다.
Table 8.
Summary of key geometry characteristics for two office building clusters
두 클러스터 모두 참조 건물 모델 개발에 포함되었으며, 이는 한국의 업무 시설 건축물 재고 내에서 뚜렷하고 의미 있는 두 가지 유형을 나타낸다. 클러스터 1은 중소규모 개발에 흔히 나타나는 전형적인 중층 업무 시설을 반영하며, 클러스터 2는 도심 업무 지구나 고밀도 도시 지역에서 자주 볼 수 있는 대형 고층 업무 시설에 해당한다. 이러한 유형 구분은 각 건물 유형에 맞춰 시뮬레이션용 모델을 구축하기 위한 기하학적 기반을 형성한다.
창면적비
각 클러스터를 대표하는 건물들을 분석한 결과, 계산된 창면적비 값은 방향에 따라 뚜렷한 차이를 보였다. 중층 업무 시설에 해당하는 클러스터 1은 창면적비가 15%에서 50%까지 분포하였으며, 서측 입면이 평균 50%로 가장 높고, 동측 입면이 15%로 가장 낮았다. 고층 업무 시설을 나타내는 클러스터 2는 방향에 따라 26%에서 47% 범위의 다소 균형 잡힌 결과를 보였으나 여전히 차이를 보였다. 비교 대상으로 사용된 DOE Medium Office 모델은 모든 입면에 대해 동일하게 33%의 창면적비를 적용하였다.
이러한 결과는 Table 9에 요약되어 있으며, 클러스터 1, 클러스터 2, 그리고 DOE 기준 모델에 대해 각 방향(동, 서, 남, 북)별 창면적과 벽면적, 그리고 해당 창면적비가 제시되어 있다. 방향별 수치는 다소 차이를 보였지만, 전체 방향에 대한 평균 창면적비는 두 클러스터 모두 약 35%로 나타났다. 해당 결과는 국내 업무 시설의 창면적비가 일반적으로 33%에서 40% 사이에 분포하며, 이는 DOE 모델과 같은 국제 기준과도 일치함을 시사한다.
모델링을 단순화하고 사례 간 일관성을 확보하기 위해, 클러스터 1과 클러스터 2의 모든 방향에 대해 창면적비(WWR) 35%를 균일하게 적용하였다. 이 값은 데이터셋에서 관찰된 경향을 반영하면서도 시뮬레이션 환경에서 실용적으로 적용 가능한 수준이다.
Table 9.
Comparison of Window and Wall Areas by Orientation for Each Cluster and DOE Medium Office
EnergyPlus 모델 생성
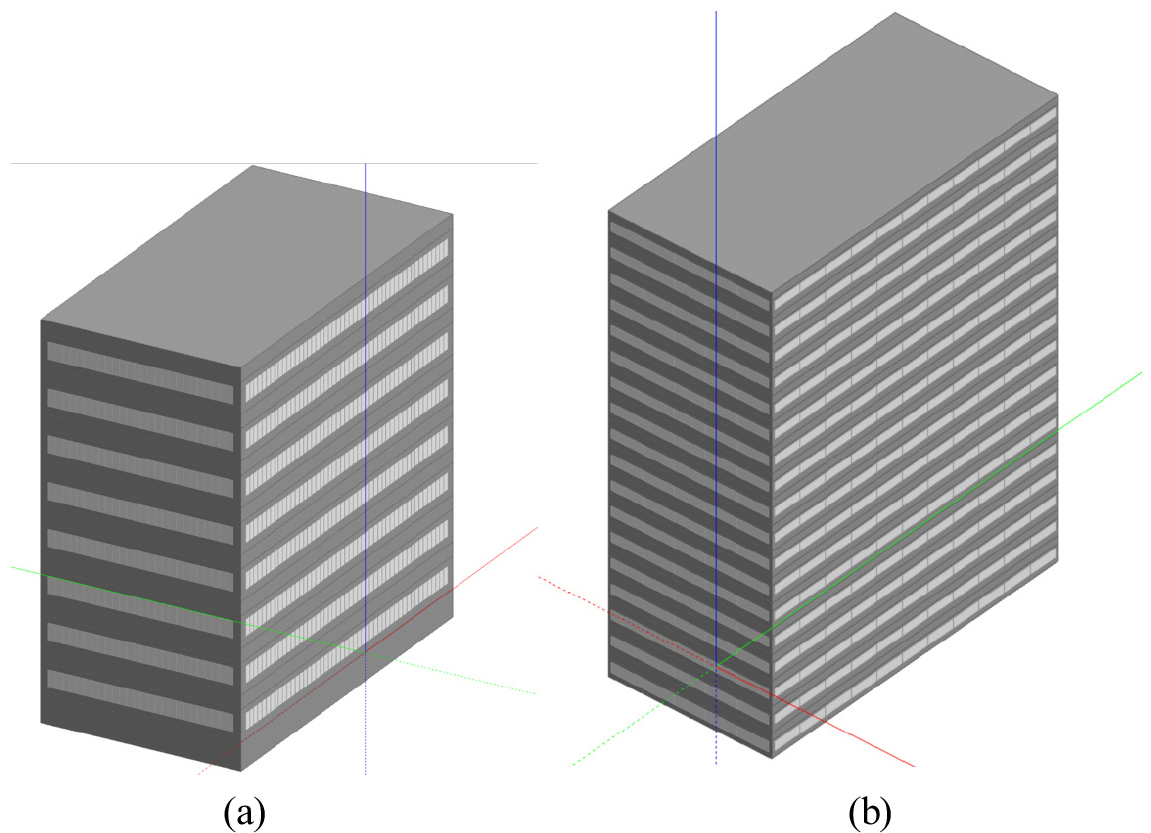
한국의 업무 시설을 대표하는 중층 및 고층 두 가지 유형의 모델이 개발되었으며, 이는 보편적인 기하학적 및 열적 특성을 반영하도록 구성되었다. 각 모델은 데이터 기반 분류를 통해 도출된 건축면적, 연면적, 용적률산정연면적, 지상 층수, 건물 높이, 장단변비 등의 주요 매개변수를 기반으로 구축되었다. 또한 모든 입면에 대해 균일한 창면적비 35%가 적용되었으며, 내부 존 구성은 표준 참조 모델링 방식에 따라 재실구역과 플레넘으로 설정되었다. 외피 구성은 국내의 최신 열성능 기준을 충족하도록 설계되었다. 모델은 DesignBuilder를 이용해 개발되었으며, EnergyPlus의 IDF 형식으로 변환되어 향후 에너지 성능 평가, 시나리오 분석 및 정책 수립 등에 활용 가능한 시뮬레이션 템플릿으로 완성되었다(Figure 10).
개발된 모델의 열적 성능을 평가하기 위해, 군집 분석을 통해 도출된 두 대표 업무 시설 유형(클러스터 1과 클러스터 2)을 대상으로 EnergyPlus를 이용한 연간 에너지 시뮬레이션을 수행하였다.
시뮬레이션에 적용된 건물 외피 및 창호의 물성치는 2015–2018년 기간에 해당하는 한국의 「건축물 에너지절약설계기준」을 기반으로 하였다. 구체적으로, 열관류율(U-value)은 외벽 0.26 W/m2·K, 바닥 0.22 W/m2·K, 지붕 0.15 W/m2·K, 창호 1.5 W/m2·K로 설정되었으며, G-value (SHGC)는 0.581로 적용되었다. 이 값들은 클러스터 1 및 클러스터 2 모델 모두에 동일하게 적용되었다.
쾌적한 실내 온열 환경 유지를 위한 난방 및 냉방 에너지 요구량 산정을 위해 IdealLoads AirSystem이 적용되었다. 또한 시뮬레이션은 장기간 평균 기상 조건을 대표하는 시간 단위 기후 데이터를 기반으로 구성된 Typical Meteorological Year (TMY) 기상 데이터를 활용하여 수행되었다. 본 연구에서는 EnergyPlus에서 제공하는 기본 TMY 기상파일 중 대상지에서 가장 가까운 인천 기상 관측소 데이터를 사용하였다.
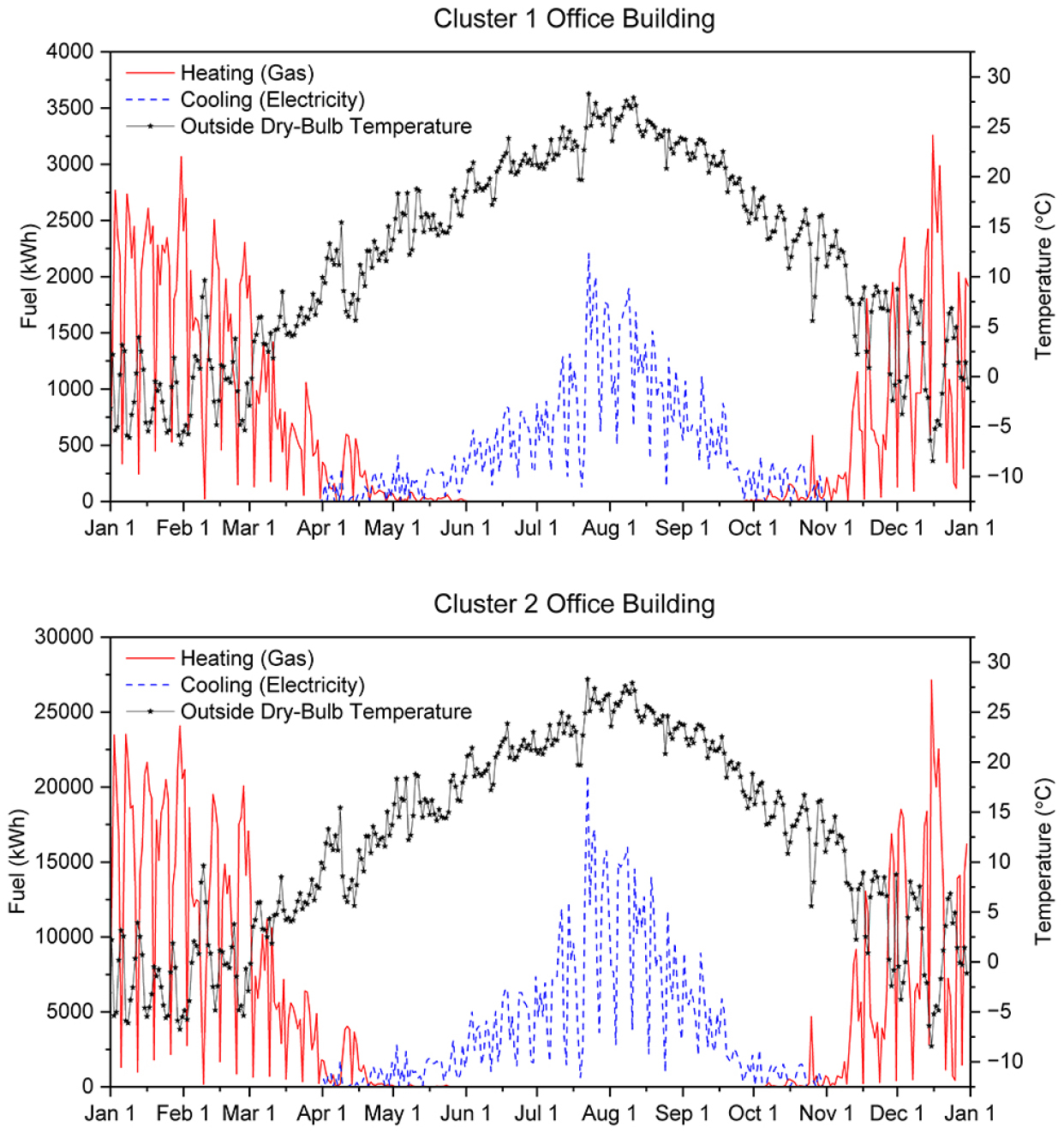
Figure 11은 TMY 연도 동안의 일별 난방 및 냉방 에너지 사용량과 이에 대응하는 일 평균 외기 온도를 요약하여 보여준다. 온도는 한국의 전형적인 연간 기후 경향을 반영하고 있으며, 8월에는 약 28℃로 최고 기온을 보였고, 1월에는 약 -8℃로 최저 기온을 나타냈다.결과는 외기 온도 변화와 일치하는 뚜렷한 계절별 경향을 보여준다. 클러스터 1의 경우, 난방 수요는 1월에 약 3,500 kWh/일로 최고치를 기록한 뒤 3월 이후 급격히 감소하였고, 11월 말부터 다시 나타났다. 냉방 수요는 6월까지는 거의 없었으며, 8월 초에 2,200 kWh/일로 정점을 찍은 후 9월에 감소하였다. 이러한 패턴은 중간 규모의 건물 특성을 반영하며, 내부 발열량이 적고 열용량이 낮아 일일 에너지 수요의 변동폭이 더 크게 나타났음을 의미한다.
반면, 고층 업무시설을 대표하는 클러스터 2는 훨씬 높은 에너지 소비를 나타냈다. 난방 수요는 12월에 하루 25,000 kWh를 초과하며, 클러스터 1의 약 7배에 달했다. 냉방 수요는 8월에 최대 20,800 kWh/일에 도달했으며, 여름 후반까지 이어지는 더 넓은 계절적 분포를 보였다. 이러한 높은 에너지 부하는 훨씬 더 큰 연면적, 증가된 열구역 수, 그리고 더 많은 내부 발열량에 기인한 것으로 분석된다.
두 건물 모두 동일한 외피 구성, 내부 발열 조건, 그리고 기후 조건을 적용하여 시뮬레이션을 수행했음에도 불구하고, 기하학적 규모와 표면대체적비(surface-to-volume ratio)의 차이는 에너지 수요 프로파일에 큰 영향을 미쳤다. 고층 모델은 더 큰 체적과 외피 면적으로 인해 누적 열교환이 증가하였고, 실내 열쾌적 조건을 유지하기 위해 더 많은 에너지가 요구되었다.
이러한 결과는 도시 에너지 성능을 평가할 때 건물 유형을 구분하는 것이 얼마나 중요한지를 강조한다. 단일 대표 모델만을 사용할 경우, 실제 건물 재고 내에서의 다양한 특성과 에너지 사용 패턴의 차이를 반영하지 못할 수 있다. 본 연구에서처럼 클러스터링 기반의 분류 기법을 도입하고 다수의 대표 모델을 개발하는 접근 방식은 보다 정밀하고 세밀한 분석을 가능하게 하며, 도시 차원의 효율적인 에너지 계획 수립과 정책 개발에 기여할 수 있다.
한계점 및 향후 연구 방향
이 연구는 국내 업무용 건축물에 대한 대표 에너지 모델을 개발하기 위한 종합적인 접근 방식을 제시한다. 제안된 방법은 에너지 성능 평가 및 시나리오 기반 분석을 지원할 수 있는 대표 건물 모델의 작성을 가능하게 한다. 그러나 몇 가지 한계점은 고려되어야 한다.
첫째, 점유, 장비, 조명, 냉난방 운전에 사용된 내부 운전 스케줄은 미국 에너지부(DOE)의 참조 모델을 기반으로 설정되었으며, 이는 한국의 실제 업무 시설의 사용 패턴이나 행태를 충분히 반영하지 못할 수 있다. 이러한 국제 표준 스케줄에 대한 의존은 향후 연구에서 국내 시뮬레이션의 정확도를 높이기 위해, 지역 특화된 내부 운전 스케줄 데이터의 표준화 필요성을 시사한다.
둘째, 존 구성은 DOE의 중층 및 대형 오피스 참조 모델을 기반으로 설정되었다. 이 방식은 시뮬레이션을 위한 일관적이고 문서화된 구조를 제공하지만, 국내 업무용 건물에서 흔히 나타나는 내부 구획의 다양성을 완전히 반영하지 못할 수 있다.
이러한 한계들을 향후 연구에서 보완한다면, 한국 업무용 건물의 특성을 보다 정확히 반영하고 시뮬레이션의 정밀도를 향상시키는 데 도움이 될 것이다.
결 론
본 연구는 대한민국 도시 환경을 반영한 대표 업무시설 건물 모델을 개발하기 위한 데이터 접근(data-driven approach)을 제안하였다. 서울 및 경기도 지역의 업무시설에 대한 종합적인 데이터를 바탕으로, 계층적 클러스터링(hierarchical clustering) 기법을 적용하여 건물들을 중층(medium-rise) 및 고층(high-rise)으로 분류하였다. 건축면적, 연면적, 용적률산정연면적, 건물 높이, 지상 층수, 장단변비 등 주요 기하학적 변수들이 클러스터링의 기준으로 활용되었다. 각 클러스터별로 다중 존(multi-zone) 구성의 대표 건물 모델이 개발되었으며, 창면적비는 실제 거리 이미지 기반 검증을 통해 도출되었고, 외피 구성은 국내 단열 성능 기준에 맞추어 설정되었다.
에너지 시뮬레이션 결과, 두 클러스터 간 열적 성능에 있어 뚜렷한 차이가 나타났으며, 이는 단일 대표 모델만으로는 지역 건물 내의 다양성을 충분히 반영하기 어렵다는 점을 확인시켜 주었다. 본 연구의 방법론은 기하학적 특성과 운영 특성의 변동성을 모델에 반영함으로써, 시뮬레이션 기반 에너지 평가의 신뢰성과 현실성을 향상시킨다.
전반적으로, 본 연구에서 제안한 모델링 접근 방식은 실제 데이터를 기반으로 한국 업무용 건축물을 표준화되고 재현 가능하게 특성화할 수 있는 방법을 제공한다. 개발된 참조 모델은 대규모 실제 건축물 데이터셋에서 도출된 형상적 특성을 반영하였으며, 외피 성능은 한국의 단열 성능 기준에 따라 설정되었다. 생성된 모델은 건축물 스톡 내의 다양한 특성을 반영하며, 에너지 시뮬레이션을 위한 참조 모델이 부족한 현재 상황에서 그 공백을 보완하는 데 기여한다. 이 모델들은 연구자 및 엔지니어뿐만 아니라 정책 입안자 및 도시 에너지 계획 수립자에게도 활용될 수 있으며, 시나리오 기반 평가, 리트로핏 전략 개발, 성능 벤치마킹 등 다양한 용도를 지원한다. 도시 에너지 문제의 복잡성이 증가함에 따라, 지역 기반의 데이터 기반 참조 모델은 효과적이고 상황에 적합한 솔루션을 설계하는 데 필수적인 요소가 될 것이다.
한편, 제안된 접근 방식은 체계적이고 실용적인 프레임워크를 제공하지만, 미국 에너지부(DOE)의 운전 스케줄과 존 구성 템플릿을 사용하는 등 일부 모델링 가정은 한국 업무용 건축물의 실제 운영 특성과 공간 배치를 완전히 반영하지 못할 수 있다. 이러한 부분들은 향후 연구에서 정교화되어 모델의 정확성과 국내 적용 가능성을 더욱 향상시킬 수 있을 것이다.
