

서 론
냉동기 데이터 생성 및 입력변수 선정
냉동기 운전 데이터 생성
스피어만 등위 상관계수를 이용한 입력변수 선정
예측 모델의 성능향상 및 평가 방법
랜덤포레스트 모델
인공신경망 모델
예측 모델 평가 방법
예측 결과 및 분석
랜덤포레스트 모델의 예측성능 결과
인공신경망 모델의 예측성능
랜덤포레스트 모델과 인공신경망 모델 비교 분석
결 론
서 론
건물에서 소비되는 에너지는 국가에서 사용하는 에너지의 40% 이상을 차지하며, 국내 건물의 전력 에너지소비량은 2013년에서 2019년 사이에 37% 증가하여 건물 에너지 소비의 절약을 위한 노력이 필요하다. 건물 에너지는 설계단계에서 에너지 절약적인 설계뿐만이 아닌 설비시스템의 적절한 운영, 제어 그리고 관리방안을 통하여 절약할 수 있다. 최근에는 BEMS (Building Energy Management System)와 같은 시스템의 도입이 활성화되면서 건물 에너지 사용량에 대한 다양한 정보를 제공하여 건물의 에너지를 효과적으로 관리가 가능해졌다. 건물 에너지 관리 방법 중에서 건축물의 에너지소비량과 수요의 정확한 예측은 설계단계에서부터 운영단계까지 에너지 성능 최적화를 위해서 반드시 필요하다. 설계단계에서는 시스템의 설계, 적정 설비 용량의 선정을 할 수 있으며, 운영단계에서는 최적제어, 적절한 운전 계획 등을 수립함으로써 에너지 성능을 향상시킬 수 있다.
이를 위해 최근에는 기계학습 방법을 이용하여 에너지 소비패턴을 분석하거나(Yoon et al., 2017) 에너지 소비 예측(Jeong and Chae, 2017)에 관한 연구들이 수행되고 있는데 대부분 건물 전체의 에너지소비량이나 건물 부하(Kim et al., 2019a)를 대상으로 에너지 예측을 수행하였다. 건물에서는 냉난방과 관련된 건축설비 시스템에서의 에너지의 절감 잠재력이 가장 크기 때문에 이들의 개별적인 에너지 소비 패턴을 이해하고 분석하여 정확한 예측이 요구되고 있으며 단일 기계학습 방법을 이용하여 예측하는 방법(Jeon and Kim, 2017; Kim et al., 2019b)이 주로 이루어지고 있어 여러 모델을 이용한 비교도 필요하다.
따라서 본 연구에서는 건물 에너지의 효과적인 관리를 위해 기계학습을 이용하여 에너지소비량을 정확하게 예측하는 연구를 수행하고자 한다. 예측은 건물에서 여름철의 냉방 에너지 소비 대부분을 차지하는 냉동기 에너지소비량을 대상으로 한다. Python을 기반으로 하여 기계학습 모델 중에서 랜덤포레스트 모델과 인공신경망 모델을 개발한 후 모델의 입력 조건들을 변화시켜가며 예측정확도를 산출하여 그 결과를 평가해가면서 예측 모델의 성능을 개선하였다. 또한 입력 조건들을 변화에 따른 두 모델의 비교를 통해 예측성능을 비교 분석하였다.
냉동기 데이터 생성 및 입력변수 선정
냉동기 운전 데이터 생성
본 연구에서 사용된 냉동기 운전 데이터는 선행된 연구(Seong et al., 2020)와 같이 업무용 표준건물의 시뮬레이션을 통해 생성된 데이터를 연구에 활용하였다. 업무용 표준건물은 DOE의 Building Energy Codes Program에서 제시한 표준건물 중 Commercial Prototype Building Models의 Large Office Building (Field et al., 2010; Deru et al., 2011)을 이용하였다. 표준건물을 시뮬레이션하는 과정에서 건물과 설비시스템의 주요 운전 스케줄, 내부 발열 조건, 냉방 설정온도는 선행연구(Seong et al., 2019)에서 활용한 것과 같이 국내의 일반적인 기준을 참고하여 Table 1과 같이 변경하였다. 기상 데이터는 서울지역의 기상자료인 TRY (Test Reference Year)format을 사용하였고 시뮬레이션 프로그램은 Energyplus 8.9를 사용 하였다. 데이터는 1시간 단위로 생성되도록 하였다. 총 데이터세트의 개수는 8760개이며 이중 냉방 기간인 5월부터 9월의 데이터 중 결측치인 0의 값을 제외한 3761개의 데이터세트를 연구에 사용하였다.
Table 1.
Simulation Condition of Reference Building Large Scale Office (Seong et al., 2019)
스피어만 등위 상관계수를 이용한 입력변수 선정
시뮬레이션 모델을 이용하여 생성된 다수의 데이터 중 기계학습 기반의 예측 모델의 입력변수로 사용할 변수들을 선정하였다. 기계학습 기반의 예측 모델은 입력변수들의 중요도의 차이와 입력변수들의 개수에 따라 예측성능에 영향을 미친다(Shin and Park, 2017; Kim et al., 2019b). 따라서 본 연구에서는 예측 모델에 사용되는 입력변수들의 설정에 따른 예측성능의 차이를 확인하고, 변수들과 냉동기 에너지소비량 사이의 상관관계를 확인하기 위하여 스피어만 등위 상관계수(Spearman rank-order correlation coefficient)를 산출한 후 입력변수로 활용하였다.
Table 2는 생성된 입력변수들과 기계학습모델이 예측하여 출력하고자 하는 냉동기 에너지소비량 간의 스피어만 등위 상관계수 산출 결과를 나타낸다. 스피어만 등위 상관계수는 -1.0에서 +1.0 사이의 값을 가지며 양의 상관관계일 경우 +1에, 음의 상관관계일 경우 -1에 가까운 값을 가진다.
Table 2.
Spearman rank-order correlation coefficient
냉동기 운전 여부를 결정하는 외기 조건 중에서 외기의 건구온도, 외기의 습구온도, 외기의 상대습도는 높은 상관관계를 보였으며, 냉동기 운전 값의 경우 냉수 공급 유량과 냉수 공급온도가 높은 상관관계를 보였다. 냉동기의 냉수 공급온도는 6.7℃의 고정값으로 설정하고 부하 변동에 따라 유량이 제어되도록 데이터를 생성하여 낮은 상관계수를 보였으며 냉수 공급 유량은 가장 높은 상관관계를 보였다.
입력변수는 양의 상관계수를 가지는 냉수 공급 유량(kg/s), 냉각수 온도(℃), 외기 건구온도(℃), 외기 습구온도(℃), 외기 노점온도(℃), 외기 상대습도(%), 가동시간, 가동날짜를 사용하였다.
예측 모델의 성능향상 및 평가 방법
본 연구에서는 Python을 이용하여 랜덤포레스트(Random Forest)와 인공신경망(Artificial Neural Network) 예측 모델을 개발하고 예측성능을 개선한 후 동일 조건에서 각 모델의 성능을 비교 분석하였다. Matlab과 Python 각 언어의 프로그래밍 특징들을 비교 분석한 연구(Ozgur et al., 2017)에서 Python이 Matlab보다 프로그래밍 작업이 더 간결하고 가독성이 좋기 때문에 학습 시에 버그가 감소하고 디버깅이 빠르며, The object-oriented programming (OOP)이 복잡한 Matlab 프로그램과는 달리 단순하고 유연한 내부 구조로 프로그래밍 과정의 접근성이 우수하다. 또한 Python은 오픈소스(open source) 개발 언어로 비용이 들지 않고 다른 프로그래밍 언어로 제작된 모듈들도 포함해 사용이 가능하다. 또한 코딩 시 변수를 사용할 때 변수 타입을 별도로 지정하지 않고 실행할 때 변수의 타입을 자동으로 검사를 실시한다. 컴파일하지 않고 인터프리터가 코드를 직접 한 줄씩 실행하는 방식으로 컴파일 과정이 필요 없고 실행 결과를 바로 확인하면서 코딩할 수 있다는 장점이 있다(Oliphant, 2007; Millman and Aivazis, 2011).
랜덤포레스트 모델
랜덤포레스트 예측 모델은 Python의 sklearn에서 제공하는 RandomForestRegressor을 사용하였으며 데이터의 계산, 그래프 작성, 통계 처리를 위한 모듈 설정을 실시하였다.
랜덤포레스트 모델의 예측성능 향상을 위해 입력변수의 개수와 훈련 데이터 크기를 변화시켜가며 예측 모델의 성능을 최적화하는 과정을 수행하였다. 입력변수의 개수는 상관관계가 가장 높은 냉수 공급 유량을 입력하는 것을 시작으로 차 순위의 변수들을 하나씩 순차적으로 추가하였으며 1개에서 8개까지 입력변수의 개수를 증가시켜가며 예측 결과를 비교하였다. 학습 데이터 크기는 50%에서 90%까지 10%씩 증가시켜가며 예측 결과를 비교하였다. 입력변수의 개수 변화 시에는 학습데이터의 크기는 80%로 고정하였고 학습데이터의 크기의 변화 시에는 입력변수의 개수를 8개로 고정하였다. Table 3은 랜덤포레스트 모델의 입력 파라미터 설정 조건을 나타낸다.
Table 3.
Condition for Setting Input Parameters for Random Forest Model
| Number of Input | 1~8 |
| Training Data Size | 50~90% |
| Predict Target | Chiller Energy Consumption (kWh) |
인공신경망 모델
인공신경망 예측 모델은 Python의 Tensorflow에서 제공하는 keras를 사용하였으며 데이터의 계산, 그래프 작성 그리고 통계처리를 위한 모듈 설정을 실시하였다. 인공신경망 모델의 예측성능 향상을 위해 랜덤포레스트와 동일한 방법으로 입력변수의 개수 증가와 학습데이터의 크기를 증가시켜가며 예측 모델의 성능을 최적화하는 과정을 수행하였다. 인공신경망의 성능을 최적화하는 과정에서는 뉴런(neuron)의 수도 함께 고려하여야 하는데 입력변수의 개수와 학습데이터의 크기를 변화할 때의 뉴런의 수는 60개로 고정하였다. 뉴런의 수를 변경하여가며 모델의 성능을 최적화할 때는 뉴런의 수를 10개부터 100개까지 10개씩 증가시켰다. 뉴런의 수를 변화시킬 때의 입력변수 개수는 8개, 훈련 데이터의 크기는 80%로 고정하였다. 인공신경망 모델의 구조는 앞서 수행된 연구(Kim et al., 2019b)를 참고하여 입력층, 은닉층, 출력층으로 구성되며 Learning Rate 0.001로, 학습 횟수(Epoch)는 100회로 설정하였으며 변경 없이 모든 경우에 일괄 적용하였다.
Table 4는 인공신경망 모델의 입력 파라미터 설정 조건을 나타낸다.
Table 4.
Condition for Setting Input Parameters for Artificial Neural Network Model
| Number of Input | 1~8 |
| Training Data Size | 50~90% |
| Number of Neuron | 10~100 |
| Predict Target | Chiller Energy Consumption (kWh) |
예측 모델 평가 방법
ASHRAE’s Guideline 14 (ASHRAE, 2002)에 의하면 계산 결과의 경우 데이터 비교 결과가 Table 5의 범위 안에 해당하면 적절하다고 판단하여 신뢰할 수 있는 결과라고 보고 있다. 본 연구에서는 CvRMSE (Coefficient of Variation of Root Mean Square Error)를 사용하였다. 각 모델의 입력 조건을 변화시킴에 따라서 10회씩 예측한 후 CvRMSE의 최대, 최소, 평균을 구하여 최종적으로 모델의 예측성능을 평가하였다.
Table 5.
Acceptable Calibration Tolerances (ASHRAE, 2002)
| Calibration Type | Index | Acceptable Value* |
| Monthly | MBEmonth | ± 5% |
| Cv (RMSEmonth) | ||
| Hourly | MBEhourly | ±10% |
| Cv (RMSEhourly) |
예측 결과 및 분석
랜덤포레스트 모델의 예측성능 결과
Table 6은 랜덤포레스트 모델의 입력개수 변화에 따른 CvRMSE을 나타낸다. 입력개수를 3개로 설정하였을 때부터 CvRMSE의 평균이 29.80%로 기준인 30%를 초과하지 않지만 최댓값이 43.94%이므로 기준에 만족하는 예측성능을 확보할 수 있다고 보기는 힘들다고 판단된다. 최솟값, 최댓값, 평균값이 모두 기준을 만족하는 경우는 입력개수가 7개 이상으로 설정하였을 때부터로 본 연구에서 랜덤포레스트모델을 이용하여 냉동기 에너지소비량을 예측하기 위해서는 입력개수를 7개 이상으로 구성한 모델이 기준 내에 허용되는 예측성능을 갖는 모델이라고 할 수 있다. 입력변수의 개수를 7개에서 8개로 증가시키면 모델의 평균 예측정확도를 1.31% 더 향상할 수 있었다.
Table 6.
Accuracy of Random forest models according to change number of inputs
Figure 1은 입력개수 변화에 따른 예측정확도를 도식화 한 것으로 입력개수를 증가시켜가며 예측정확도를 평가한 결과 비교적 상관관계가 낮은 입력변수라도 예측성능에 영향을 미치며, 예측정확도인 CvRMSE는 입력변수의 개수가 증가함에 따라 감소하여 예측성능이 향상되는 것으로 나타났다.
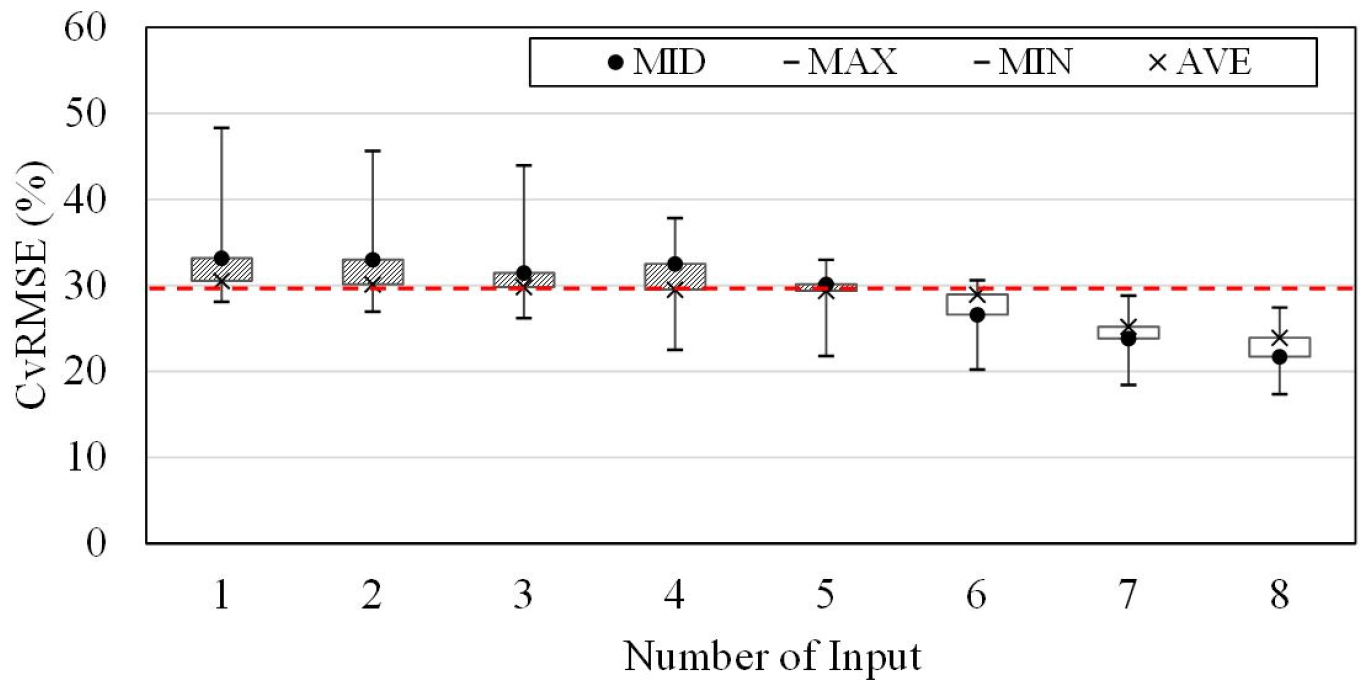
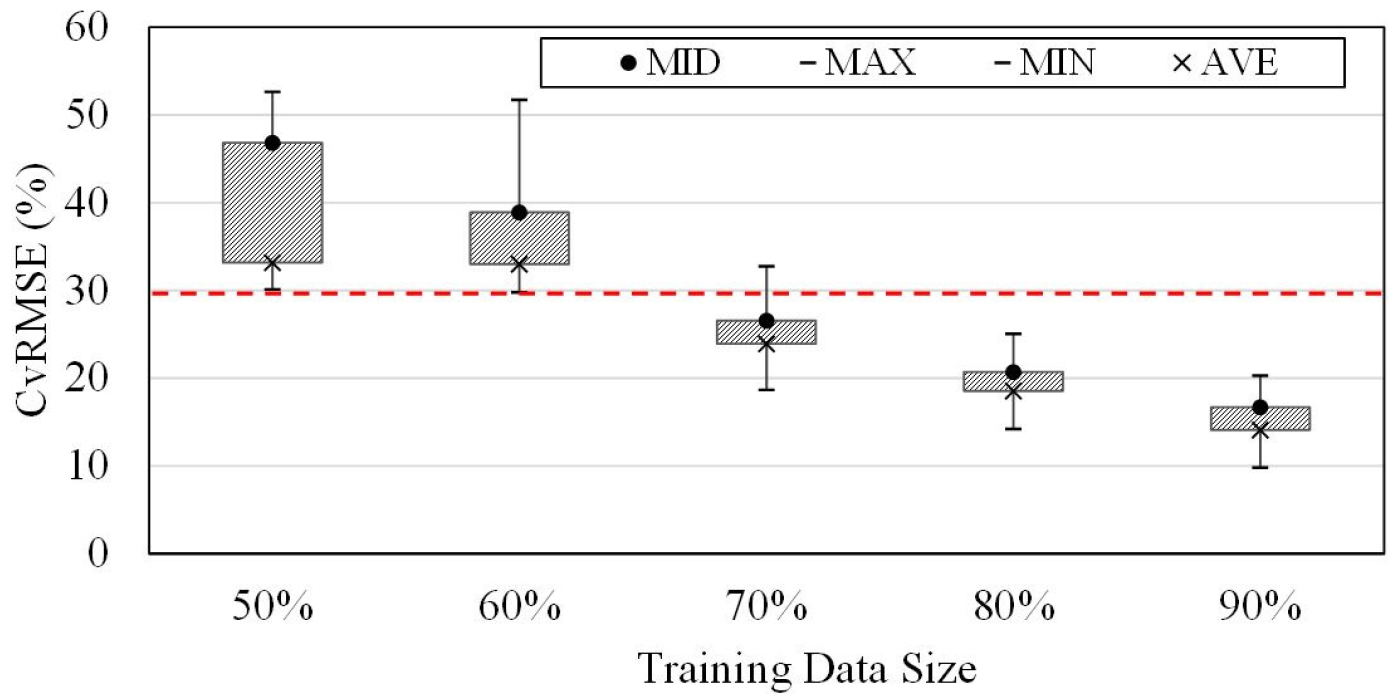
Table 7은 랜덤포레스트 모델의 훈련 데이터의 크기의 변화에 따른 예측 결과의 CvRMSE 값을 나타낸다. 훈련 데이터의 크기가 70%로 설정하였을 때 CvRMSE의 평균값이 23.91%로 기준을 만족하지만 최댓값이 32.78%로 기준을 초과하여 예측성능을 확보하였다고 보기는 어렵다. 최솟값, 최댓값, 평균값이 모두 기준을 만족하는 경우는 학습데이터의 크기를 80%로 조정한 모델로 본 연구에서 랜덤포레스트모델을 이용하여 냉동기 에너지소비량을 예측하기 위해서는 학습데이터의 크기를 80% 이상으로 구성한 모델이 기준 내에 허용되는 예측성능을 갖는 모델이라고 할 수 있다. 학습 데이터 크기를 80%에서 90%까지 증가시키면 모델의 평균 예측정확도는 4.48% 더 향상되었다.
Table 7.
Accuracy of Random forest models according to change training data size
| Training Data Size | Maximum | Minimum | Average | Standard Deviation |
| 50 | 52.64 | 30.12 | 33.15 | 13.79 |
| 60 | 51.73 | 29.76 | 33.01 | 5.93 |
| 70 | 32.78 | 18.66 | 23.91 | 2.52 |
| 80 | 25.07 | 14.23 | 18.56 | 2.11 |
| 90 | 20.29 | 9.82 | 14.08 | 2.59 |
Figure 2는 학습 데이터 크기에 따른 랜덤포레스트모델의 예측정확도를 도식화 한 것으로 학습 데이터 크기를 증가시켜가며 예측정확도를 평가한 결과 예측정확도인 CvRMSE는 훈련 데이터의 크기가 증가함에 따라 감소하여 예측성능이 향상되는 것으로 나타났다. 훈련 데이터의 크기가 증가할수록 많은 데이터를 훈련에 사용하여 더 높은 예측성능을 확보할 수 있지만, 훈련에 사용되는 데이터의 양이 증가하는 만큼 예측 모델의 예측 기간이 단축된다. 기계학습 기반의 예측 모델은 예측 기간을 고려하여 학습데이터와 평가데이터의 크기의 비율을 적절히 조정하는 것이 중요하다 판단된다.
인공신경망 모델의 예측성능
Table 8은 인공신경망 모델의 입력변수의 개수 변화에 따른 예측 결과의 CvRMSE 값을 나타낸다. 인공신경망 모델도 랜덤포레스트모델과 마찬가지로 입력변수의 개수가 증가할수록 예측성능 또한 향상됨을 확인할 수 있었다. 인공신경망 모델은 입력변수를 3개로 구성한 모델부터 CvRMSE의 평균값은 26.90%로 예측성능 기준을 만족하지만 최댓값이 38.39%로 기준을 초과하여 예측성능을 확보하였다고 보기는 어렵다. 입력변수의 개수가 4개로 설정했을 때부터 최솟값, 최댓값, 평균값이 모두 기준을 만족하는 예측성능을 나타냈으며 랜덤포레스트모델에서 8개의 모든 입력변수의 개수를 사용한 모델보다 평균 예측정확도가 5.48% 향상되었다. 따라서 인공신경망 모델의 경우 같은 조건에서 랜덤포레스트모델 보다 적은 입력변수로 모델을 구성하여도 우수한 예측성능을 확보할 수 있다고 판단된다.
Table 8.
Accuracy of ANN models according to change number of inputs
Figure 3은 입력개수 변화에 따른 예측정확도를 도식화 한 것으로 인공신경망 모델도 랜덤포레스트모델과 마찬가지로 비교적 상관관계가 낮은 입력변수라도 예측성능에 영향을 미치며, 예측정확도인 CvRMSE는 입력변수의 개수가 증가함에 따라 감소하여 예측성능이 향상되는 것으로 나타났다. 8개의 모든 입력변수를 사용하여 모델을 구성하였을 때 예측정확도는 4개의 입력변수로 모델을 구성하였을 때보다 3.58% 더 향상되었다.
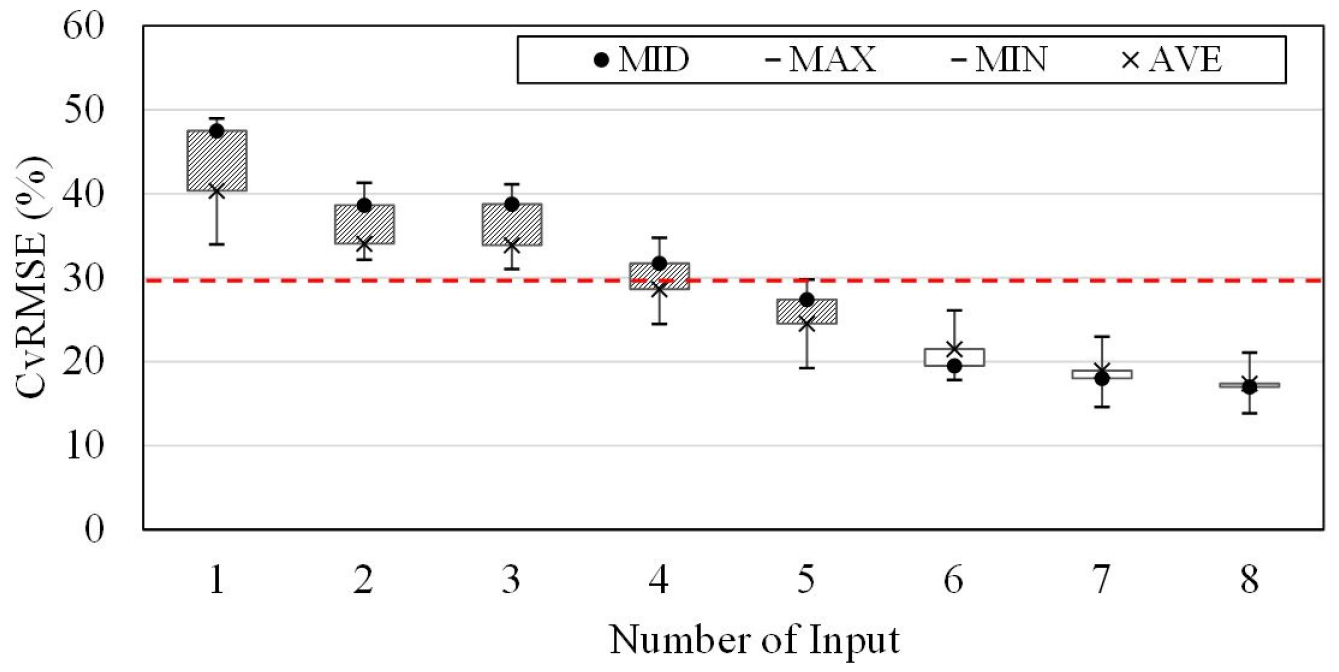
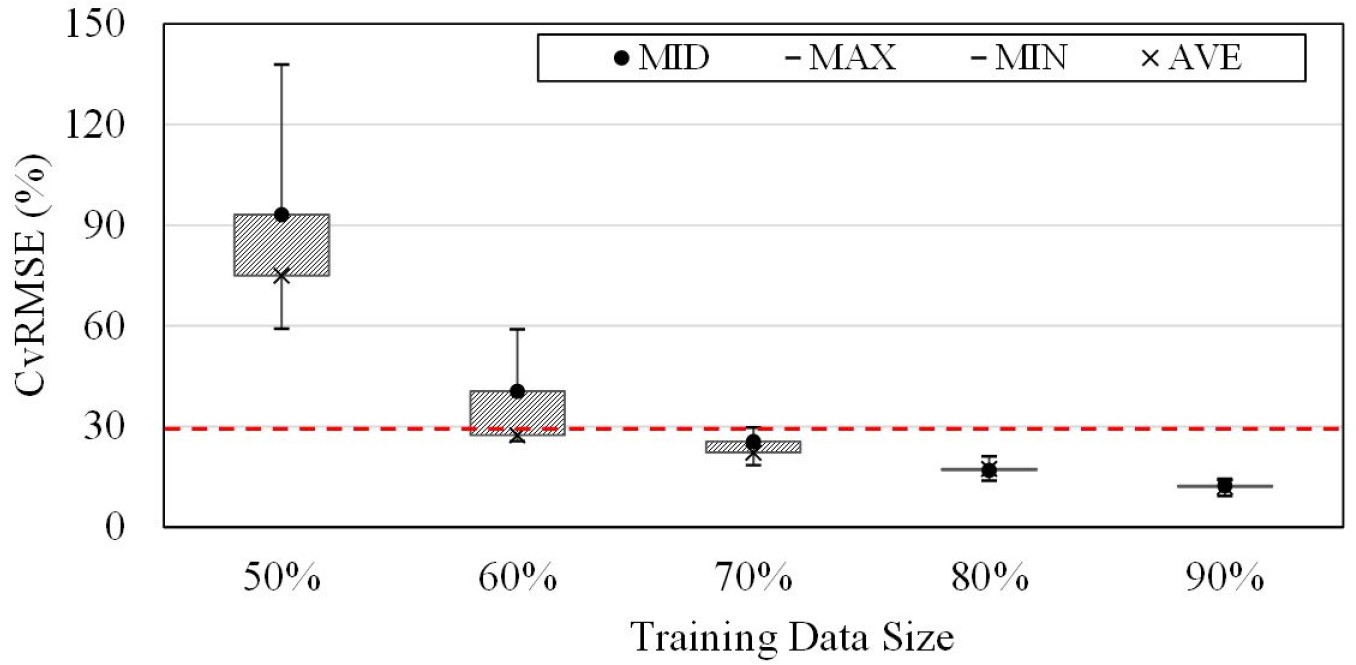
Table 9는 인공신경망 모델의 학습데이터의 크기의 변화에 따른 예측 결과의 CvRMSE 값을 나타낸다. 인공신경망 모델에서도 랜덤포레스트 모델과 마찬가지로 학습데이터의 크기가 증가함에 따라 예측성능도 향상되는 것을 확인할 수 있었다.
Table 9.
Accuracy of ANN models according to change training data size
| Training Data Size | Maximum | Minimum | Average | Standard Deviation |
| 50 | 137.87 | 59.18 | 75.02 | 18.81 |
| 60 | 59.00 | 25.70 | 27.40 | 13.24 |
| 70 | 29.79 | 18.53 | 22.30 | 3.20 |
| 80 | 21.12 | 13.87 | 17.40 | 0.42 |
| 90 | 14.43 | 9.4 | 11.99 | 0.31 |
학습데이터의 크기가 60%로 설정하였을 때 CvRMSE의 평균값이 27.40%로 기준을 만족하지만 최댓값이 59.00%로 기준을 초과하여 예측성능을 확보하였다고 보기는 어렵다. 최솟값, 최댓값, 평균값이 모두 기준을 만족하는 경우는 학습데이터의 크기를 70%로 조정한 모델로 본 연구에서 인공신경망 모델을 이용하여 냉동기 에너지소비량을 예측하기 위해서는 학습데이터의 크기를 70% 이상으로 구성한 모델이 기준 내에 허용되는 예측성능을 갖는 모델이라고 할 수 있다. 학습데이터의 크기를 70%로 하였을 때보다 학습데이터의 크기를 80%로 증가시키면 모델의 평균 예측정확도는 4.9% 더 향상되었고, 학습데이터의 크기를 90%로 증가시키면 모델의 평균 예측정확도는 10.31% 더 향상되었다.
Figure 4는 학습데이터 변화에 따른 예측정확도를 도식화 한 것으로 학습 데이터 크기를 증가시켜가며 예측정확도를 평가한 결과 예측정확도인 CvRMSE는 랜덤포레스트 모델과 마찬가지로 훈련 데이터의 크기가 증가함에 따라 감소하여 예측성능이 향상되는 것으로 나타났다. 하지만 랜덤포레스트 모델과 비교하였을 때 학습데이터의 크기가 50%인 경우 오히려 예측성능은 더 좋지 않지만, 학습데이터의 크기를 60%로 하였을 때부터 예측성능이 급격히 향상되는 것을 확인할 수 있었다.
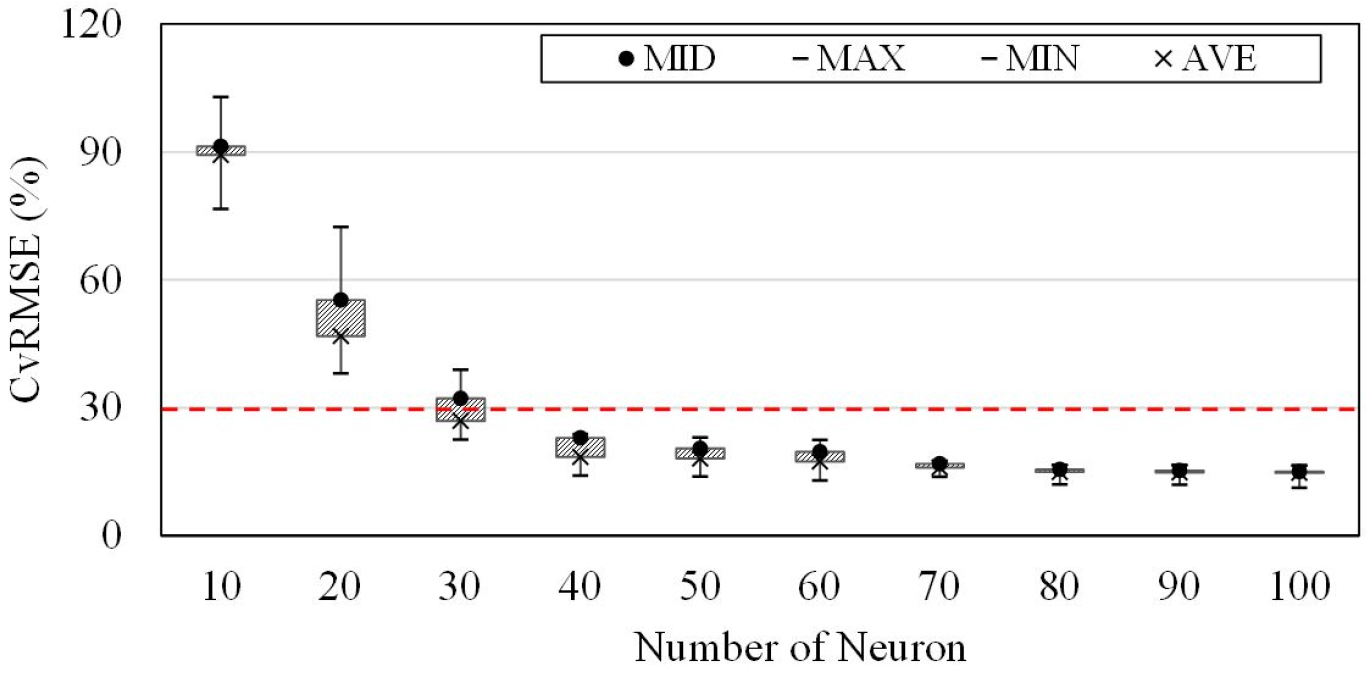
인공신경망 모델은 추가로 뉴런 수 조정을 통해 모델의 예측성능을 향상할 수 있다. Table 10은 인공신경망 모델의 뉴런 개수의 변화에 따른 예측 결과의 CvRMSE 값을 나타낸다. 뉴런의 개수가 40개 이상일 경우, 모든 값이 기준에 만족하였다. 뉴런의 개수를 80개 이상에서는 뉴런의 수를 증가시켜도 CvRMSE값이 약 0.1% 정도만 증가하여 예측성능에 큰 차이를 보이지 않았다.
Table 10.
Accuracy of ANN models according to change number of neuron
Figure 5는 뉴런 수 변화에 따른 예측정확도를 도식화 한 것으로 뉴런의 개수를 증가시켜가며 예측정확도를 평가한 결과 CvRMSE는 뉴런의 개수가 증가함에 따라 감소하여 예측성능이 향상되는 것으로 나타났다. 인공신경망 모델은 뉴런 수의 증가에 따라서 예측성능이 향상되지만, 일정 수준의 예측성능까지 도달한 후에는 뉴런의 수가 모델의 예측성능에 크게 영향을 주지 않는 것으로 판단되며 뉴런 수 조정에 의해 일정한 예측성능을 확보한 후에는 학습에 소요되는 시간을 감소시키는 것이 더 유리하다.
랜덤포레스트 모델과 인공신경망 모델 비교 분석
랜덤포레스트 모델과 인공신경망 모델의 예측성능을 비교하기 위하여 입력변수의 개수 변화에 따른 예측성능과 학습데이터의 변화에 따른 예측성능을 비교 평가하였다.
Table 11은 랜덤포레스트 모델과 인공신경망 모델의 입력변수의 개수 변화에 따른 CvRMSE의 평균값을 나타낸다. 랜덤포레스트 모델과 인공신경망 모델 모두 입력변수의 개수를 3개로 하였을 때부터 기준에 적합한 예측성능을 보였다. 그러나 입력변수의 개수를 3개에서 8개로 증가시키었을 때 인공신경망 모델이 랜덤포레스트 모델보다 9.01% 더 우수한 예측성능을 나타내었으며 랜덤포레스트 모델은 예측정확도가 5.89% 향상되는 반면 인공신경망 모델은 예측정확도가 12% 향상되어 입력변수 증가에 따른 예측성능의 개선 효과는 인공신경망 모델이 더 우수한 것으로 나타났다. 따라서 인공신경망 모델이 입력변수 증가에 따른 예측성능 개선 효과도 훨씬 더 크고, 적은 수의 입력변수로 모델을 구성하여도 우수한 예측성능을 확보할 수 있다.
Table 11.
Accuracy comparison between random forest and artificial neural network model according to change number of inputs
| Number of Input | ||||||||
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | |
| Random Forest | 30.53 | 30.11 | 29.80 | 29.50 | 29.38 | 28.93 | 25.22 | 23.91 |
| Artificial Neural Network | 89.26 | 46.85 | 26.90 | 18.48 | 18.13 | 17.40 | 15.96 | 14.90 |
Table 12는 랜덤포레스트 모델과 인공신경망 모델의 학습데이터의 크기 변화에 따른 CvRMSE의 평균값들을 나타낸다. 랜덤포레스트 모델은 학습데이터의 크기를 70%로 조정하였을 때부터 기준에 만족하는 예측성능을 보여주지만, 인공신경망 모델은 학습데이터를 60%로 조정하였을 때부터 기준에 만족하는 예측성능을 보여준다. 학습데이터의 크기가 70%일 때 예측정확도는 인공신경망 모델이 1.60% 우수하였고 학습데이터의 크기가 80%일 때 예측정확도는 인공신경망 모델이 1.16% 우수하였으며 학습데이터의 크기가 90%일 때 예측정확도는 2.09% 더 우수하였다. 학습데이터의 크기를 70%에서 90%로 증가시켰을 때 인공신경망 모델이 랜덤포레스트 모델보다 2.09% 더 우수한 예측성능을 나타내었으며 랜덤포레스트 모델은 예측성능이 9.83% 향상됐지만 인공신경망 모델은 예측성능이 10.31% 향상되어 학습 데이터 크기 변화에 따른 예측성능 개선 효과도 훨씬 더 우수한 것으로 나타났다. 따라서 인공신경망 모델이 학습데이터 증가에 따른 예측성능 개선 효과도 훨씬 더 크고 학습데이터와 평가데이터의 비율의 크기 조정과 예측 기간 선정에서 훨씬 더 유리하다.
결 론
본 연구에서는 Python 프로그래밍을 기반으로 기계학습 모델들을 이용하여 냉동기의 에너지소비량을 정확하게 예측하기 위해서 입력변수의 개수 변화와 학습 데이터 크기 조정이 각 모델의 예측성능변화에 미치는 영향을 비교하고 평가하였다. 기계학습 모델은 랜덤포레스트 모델과 인공신경망 모델을 이용하였으며 결과들을 통해 도출된 결론은 다음과 같다.
랜덤포레스트 모델과 인공신경망 모델 모두 출력값과 비교적 상관관계가 낮은 입력변수일지라도 입력변수의 개수를 증가시킴으로써 예측성능을 향상할 수 있었고, 학습데이터의 비율을 높일수록 예측성능을 향상할 수 있었다. 랜덤포레스트 모델의 경우 입력변수의 개수를 7개로 하였을 때부터 기준에 허용되는 예측성능을 갖는 것으로 나타났으며 입력변수의 개수를 최대로 증가시켜 CvRMSE는 23.91%까지 모델의 예측성능이 개선되었다. 학습데이터의 크기는 80%로 하였을 때 기준에 허용되는 예측성능을 갖는 것으로 나타났으며 학습데이터의 크기를 최대로 증가시켜 CvRMSE가 14.08%까지 모델의 예측성능이 개선되었다.
인공신경망 모델의 경우 입력변수의 개수를 4개로 하였을 때부터 기준에 허용되는 예측성능을 갖는 것으로 나타났으며 입력변수의 개수를 최고로 증가시켜 CvRMSE가 최대 14.90%까지 모델의 성능이 개선되었다. 학습데이터의 크기는 70%로 하였을 때 기준에 허용되는 예측성능을 갖는 것으로 나타났으며 학습데이터의 크기를 최대로 증가시켜 CvRMSE가 최대 11.99%까지 모델의 성능이 개선되었다. 인공신경망 모델은 뉴런 수의 증가에 따라서 예측성능이 향상되지만, 일정 수준의 예측성능까지 도달한 후에는 뉴런의 수가 모델의 예측성능에 크게 영향을 주지 않아 뉴런 수 조정에 의해 일정한 예측성능을 확보한 후에는 학습에 소요되는 시간을 감소시키는 것이 더 유리하다.
입력변수 증가에 따른 예측성능의 개선 효과와 학습데이터 증가에 따른 예측성능 개선 효과를 비교하여 분석한 결과 냉동기 에너지소비량 예측에는 랜덤포레스트 모델보다 인공신경망 모델이 더 우수한 예측성능을 갖는 것으로 나타났으며 모델을 입력변수의 사용과 학습데이터의 크기 조정에도 훨씬 더 유리하다.
후속 연구에서는 모델의 예측성능에 영향을 줄 수 있는 다른 파라미터의 조정을 통한 성능 평가가 필요하다. 또한 신경망 모델은 CNN (Convolutional Neural Network), RNN (Recurrent Neural Network), LSTM (Long Short-Term Memory model)과 같은 다양한 구조를 가진 신경망 모델이 존재하므로 이와 같은 모델을 활용한 연구도 수행되어야 할 것이다. 기계학습 기반의 에너지소비량 예측과 관리방안을 현장에 적용하기 위해서는 시뮬레이션 모델을 이용하여 생성된 데이터가 아닌 실측 데이터를 활용하여 모델의 예측성능 검증이 더 유용할 것으로 판단되며, 건물에서 에너지가 소비되는 공기조화기, 보일러, 펌프, 송풍기, 냉각탑과 같은 여러 설비시스템에 대하여 에너지소비량 예측 모델을 적용하고 예측성능을 평가해야 한다. 최종적으로는 개발된 모델을 기반으로 하는 운영과 제어에 관한 연구를 진행할 예정이다.
