

서 론
전 세계적으로 기후변화와 탄소 배출은 시급한 환경 문제로 대두되고 있으며, 탄소 배출에 있어 주요한 요인 중 하나인 건물 분야에도 관심이 높아지고 있다. 이에 따라 탄소 배출 저감을 목적으로 건물 특성과 기후 요인을 반영한 에너지 사용량 모델을 구축하고 그린리모델링 수행 효과를 예측하고자 하는 연구들이 활발히 수행되고 있다. 특히 국내에서는 벤치마킹을 위한 건물 및 에너지 데이터를 적극적으로 수집하여 기후 및 건물 요인이 에너지 사용 강도(Energy Use Intensity, EUI)에 미치는 영향을 분석하고 있으며(Kim et al., 2019), 신속한 분석을 위해서는 입력 변수를 최소화하면서도 신속하게 모델을 구축할 수 있는 장점을 가진 데이터 기반 접근법을 고려할 수 있다(Ko and Park, 2021).
하지만 기존의 데이터 기반 모델링 기법은 입력 변수와 출력 변수 간의 변화 관계, 즉 데이터 간 통계적 상관관계에만 주로 초점을 맞추며, 인과 메커니즘을 명시적으로 고려하지 않는다. 이로 인해, 거주자 행동과 같은 예측 불가능한 요소나 변수 간 복잡한 상호의존성이 포함될 경우 분석 결과에 편향이 발생할 수 있다(Chen et al., 2022). 또한 우연히 발생한 사건을 유의미한 연관으로 오해할 가능성이 있으며, 예측 과정에 대한 설명 가능성 또한 제한적이므로, 단순한 상관분석을 넘어선 대안적 접근법을 고려할 필요가 있다. 이러한 맥락에서, 통계적 연관성뿐만 아니라 시간적 인과관계까지 함께 고려할 수 있는 인과 분석 기법은 유망한 대안으로 평가된다(Bareinboim et al., 2022).
따라서, 원인과 결과의 관계, 즉 인과관계를 고려하는 인과추론 방법을 적용하여 건물 및 기후 요인 간 관계에 대한 설명력을 증가시키고자 하는 연구가 수행되고 있다. Zhou et al. (2023)에서는 중국 도시들에 대한 에너지 정책의 효과를 인과추론을 통해 통계적으로 분석 가능함을 증명하고, Sun et al. (2024)에서는 열쾌적성 분석에 있어 인과방향 설정에 따라 전혀 다른 의미의 인과관계 해석이 가능하다는 것을 증명하였으며, Mun and Park (2025)에서는 인과관계 분석을 통해 해석 가능한 제어 전략이 개발 가능함을 설명하였다.
이와 같이 건물 에너지 분야에서도 인과추론의 유용성은 입증되고 있으나 인과관계 구조를 이해하고 설계하는 부분은 이루어지지 않고 있다. 특히, 건물 및 기후 요인 간의 실체적 인과 메커니즘에 대한 기초 연구가 부족하고, 판단해야 하는 변수의 수가 많아질수록 경험적 지식만으로 인과관계를 식별하는 데에는 한계가 존재하기에 관측 데이터를 기반으로 직접 인과관계를 추론하는 접근이 필수적이다(Nogueira et al., 2022). 인과발견(causal discovery)은 주어진 데이터셋을 바탕으로 변수 간의 인과관계를 식별하고 해석하기 위한 접근 방식으로(Spirtes et al., 2000), 이러한 인과 구조를 밝혀냄으로써 단순한 상관관계를 넘어서 데이터에 내재된 의존성을 파악하고, 예측 모델의 정확도와 의사결정 과정의 신뢰성을 향상시킬 수 있다(Eberhardt, 2017).
이에 본 연구에서는 인과 연구에 대한 파일럿 테스트의 일환으로, 한국의 기상 데이터를 대상으로 널리 사용되는 두 가지 인과발견 알고리즘—Peter-Clark (PC) 알고리즘과 Fast Causal Inference (FCI) 알고리즘—을 적용하고, 이들이 도출한 인과 구조를 비교 분석하였다. 또한 발견된 구조의 신뢰성을 검증하기 위해 순열 검증(permutation test)과 반복 검증(repetition test)이라는 두 가지 방법을 제안한다. Figure 1에 나타낸 바와 같이, 본 실험은 다음의 세 단계로 구성된다:
1. 기상 데이터 전처리 및 연구자 설계 인과 구조 정의
2. PC 및 FCI 알고리즘을 이용한 인과 구조 도출
3. 순열 검증 및 반복 검증을 통한 결과 비교 및 분석
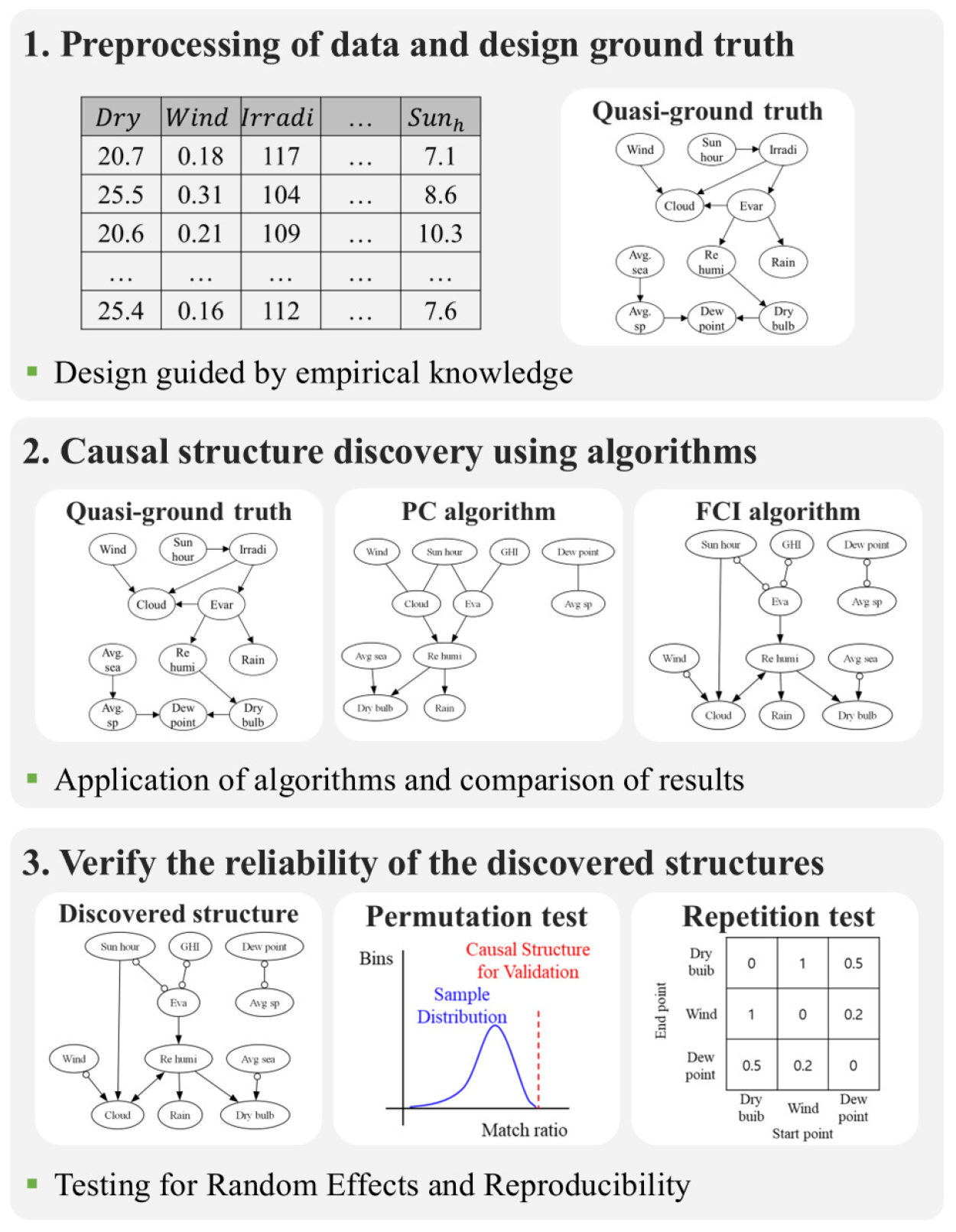
연구방법
인과발견 알고리즘
인과발견은 데이터에 기반하여 변수 간의 인과관계를 분석하는 방법으로, 변수 간 연관성은 물론 인과적 방향성 정보를 제공 가능하다. 적은 수의 변수를 포함하는 데이터셋의 경우, 인과구조 분석에 있어 경험적 지식이나 기존의 수식 기반 접근만으로도 충분한 경우가 많다. 그러나 고려해야 할 변수의 수가 증가함에 따라 경험적 지식에만 의존하는 방식에는 한계가 분명해지며, 이에 따라 인과발견 기법을 활용한 인과관계 식별을 위한 기본적인 틀과 가이드라인의 필요성이 대두된다. 본 연구에서는 다양한 인과발견 기법 중에서 변수 간 조건부 독립성 검정을 통해 인과구조를 탐색하는 제약 기반 방법(constraint-based methods)을 선정하였으며, 이 범주에서 널리 사용되는 Peter-Clark (PC) 알고리즘과 Fast Causal Inference (FCI) 알고리즘을 활용하였다.
PC 알고리즘(Spirtes et al., 2001)은 관측되지 않은 교란 변수(unobserved confounders)가 존재하지 않는다는 가정하에 인과구조를 발견하는 방법으로, 각 변수 쌍 간의 조건부 독립성을 검정하여, 독립성이 확인된 경우 두 변수 간 연결을 제외하고 남아 있는 연결들에 대해 방향을 설정하여 인과 그래프를 완성한다(Figure 2(a)). 그러나 PC 알고리즘은 숨겨진 교란 변수가 없다는 가정 하에 작동하기 때문에, 실제로 이러한 교란 요인이 존재할 경우 인과관계를 정확하게 식별하는 데 어려움이 있을 수 있다.
FCI 알고리즘(Spirtes et al., 2001)은 PC 알고리즘을 기반으로 하지만, 숨겨진 교란 변수의 존재를 허용한다는 점에서 차별화된다. 일부 또는 모든 교란 변수가 관측되지 않은 상황에서도 작동할 수 있도록 설계되었으며, 초기 변수 간 연결 제거 절차는 PC 알고리즘과 유사하지만, 인과관계 방향성을 설정할 때 잠재된 변수의 영향을 고려함으로써 실제 환경에서 더욱 유용한 정보를 제공할 수 있다(Figure 2(b)). 본 연구에서는 Python의 causal-learn 패키지(Zheng et al., 2024)를 사용하여 PC 및 FCI 알고리즘을 구현하였다. 조건부 독립성 검정을 위해 Fisher- Z 검정을 적용하였으며, 개별 부분 상관 검정의 유의수준(alpha)은 기본값인 0.05로 설정하였다.
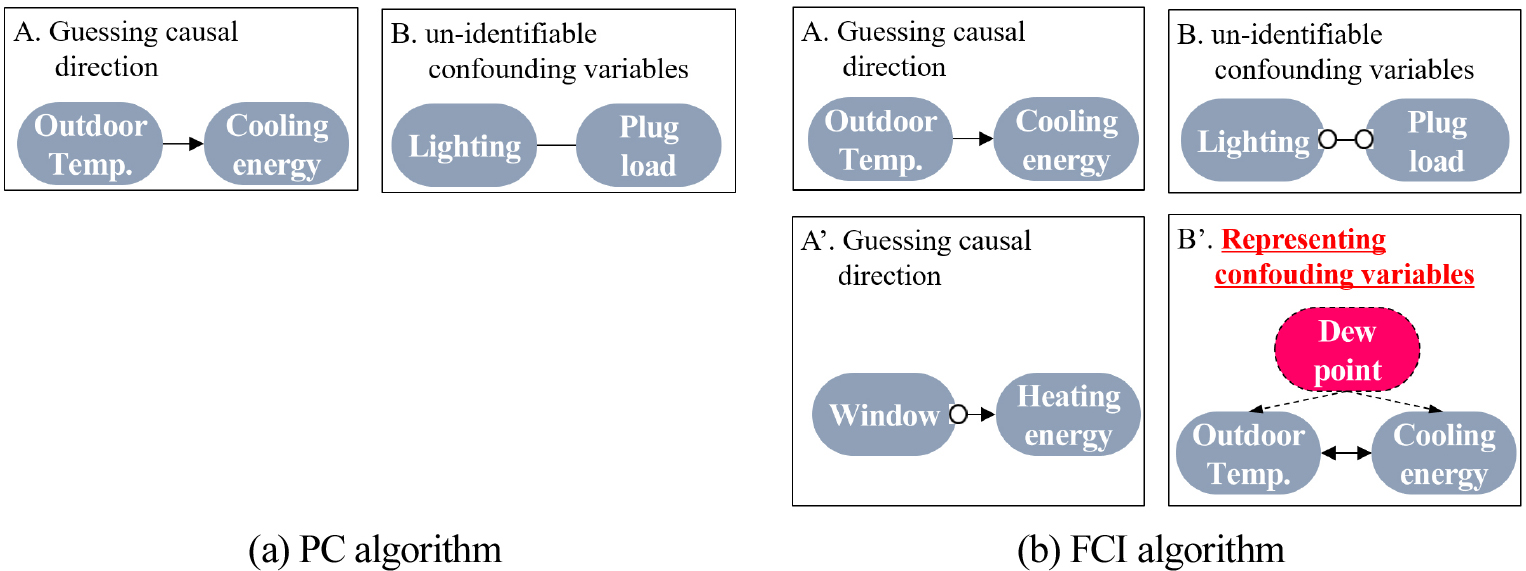
인과방향 표현
PC 알고리즘과 FCI 알고리즘은 모두 유향 비순환 그래프(directed acyclic graphs, DAGs)를 통해 노드와 노드간 정보 흐름을 표현한다. 다만, 인과 방향(edge)에 대한 표현에 차이가 있다. 예를 들면, PC 알고리즘은 “―”, “→” 두 가지로만 엣지를 표현하는데 “―” 은 특정 신뢰도 수준(p-value)으로 인과 방향을 식별하기 어려운 경우이다. 한편 FCI 알고리즘은 “→”, “↔”,“∘→”, “∘─∘” 네 가지로 엣지를 표현한다. 원 기호(“∘”)를 통해 노드 간 정보 방향 불확실성을 표현하며, 쌍방향 기호(“↔”)를 통해 노드 간 숨겨진 교란요인 가능성도 표현한다. 예를 들면, “A∘→B”의 경우, A와 B 사이에 교란 요인이 있을 수 있으나 A에서 B로의 정보 흐름은 확정적이며, B에서 A로의 정보 흐름은 없다는것을 의미한다. “A∘─∘B”의 경우 A와 B노드 간 상관성은 있으나 인과성은 유의하지 않음을 뜻한다(PC 알고리즘 “―”와 동일). “A↔ B”는 A와 B사이에 숨겨진 교란요인이 있음을 뜻한다(Spirtes et al., 2013).
인과방향 탐색
PC 알고리즘의 동작은 5가지 단계로 구성된다(Figure 3, Spirtes et al., 2001).
•Step1. 모든 변수들 사이 무방향 에지가 그려진 초기 그래프 작성
•Step2. 모든 변수 쌍의 무조건부 독립성 검증 및 관련 에지 제거
예: X ⊥ Y 이면 X-Y 제거(카이제곱 검정, G-test, 또는 상관계수 검정 등)
•Step3. 모든 변수 쌍 (X, Y)에 대해 다른 변수 집합 Z를 조건으로 하여 조건부 독립성 검정
예: X ⊥ Y | Z 성립시 에지 X-Y 제거(이 과정을 조건부 집합 크기를 늘려가며 반복)
•Step4. 세 변수 X-Z-Y가 연결되어 있고, X와 Y가 Z를 조건으로 할 때 독립아닐시(X⊥/ Y | Z) 충돌부 구조로 방향 설정(X→Z←Y)
•Step5. 방향전파(orientation propagation)에 따라 순환 방지, 비콜라이더 유지, 추가적 방향성 제약 등을 고려하여 나머지 방향 결정(Meek, 2013)
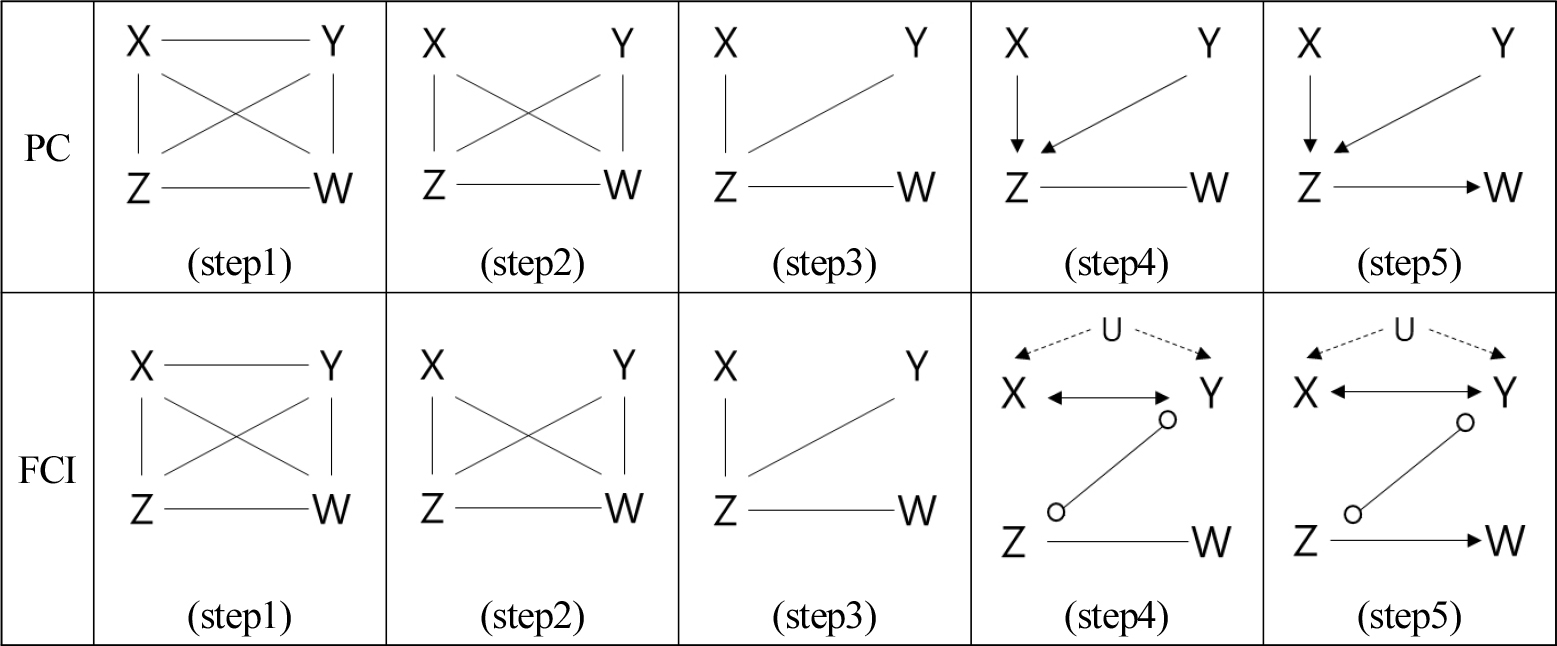
FCI 알고리즘 동작은 PC와 유사하며 잠재 변인 탐지하는 부분에서 차이가 있다. 예를 들면, Step3 뼈대를 만드는 과정은 유사하나, Step4의 충돌부 Z 통제를 통해 X와 Y의 독립성 위배로 판단되는 경우(X⊥/ Y | Z), X와 Y 사이에 숨겨진 공통원인(잠재변인)을 탐지한 것으로 간주하고 X↔ Y로 표현한다. Step5에서는 모든 다른 변수(X, Y)가 Z를 조건화했을 때 W의 독립성 유무, Z의 정보병목 역할(information bottleneck) 등 전체 패턴을 고려하여 Z→W로 선택한다(Spirtes et al., 2001; Meek, 2013).
인과구조 검증
Assaad et al. (2022)에서는 인과발견 모델의 정확도를 평가하기 위한 방법으로 합의된 정답 구조(golden rule)와 비교하여 F1-score를 계산하는 접근 방법을 제안한 바 있다. 그러나 건물 에너지 분야는 아직 관찰연구(observational study) 초기 단계에 있으며(Choi et al., 2024; Kim et al., 2024a; Kim et al., 2024b; Kim et al., 2024c; Shin et al., 2024), 변수 간 인과 구조에 대한 보편적으로 수용된 기준이 아직 정립되지 않은 상황이므로 기존 방식과는 다른 대안적 접근 방법이 필요하다. 따라서, 본 연구에서는 기상 데이터에 대하여 기존에 밝혀진 정답 구조가 없는 상황을 가정하고, 해당 상황에서 발견된 인과 구조의 신뢰성을 평가하기 위한 검증 방법으로 순열 검증(permutation test)과 반복 검증(repetition test)이라는 두 가지 방식을 제안한다. 순열 검증은 “발견된 구조는 우연히 발생한 것이다”라는 귀무가설을 통계적으로 검증하는 접근으로, Figure 4와 같이 각 변수 열의 값을 무작위로 섞은 데이터셋을 반복 생성하고 이들로부터 도출된 구조와 원래 발견된 구조 간 일치율을 측정하여 가설을 검증한다.
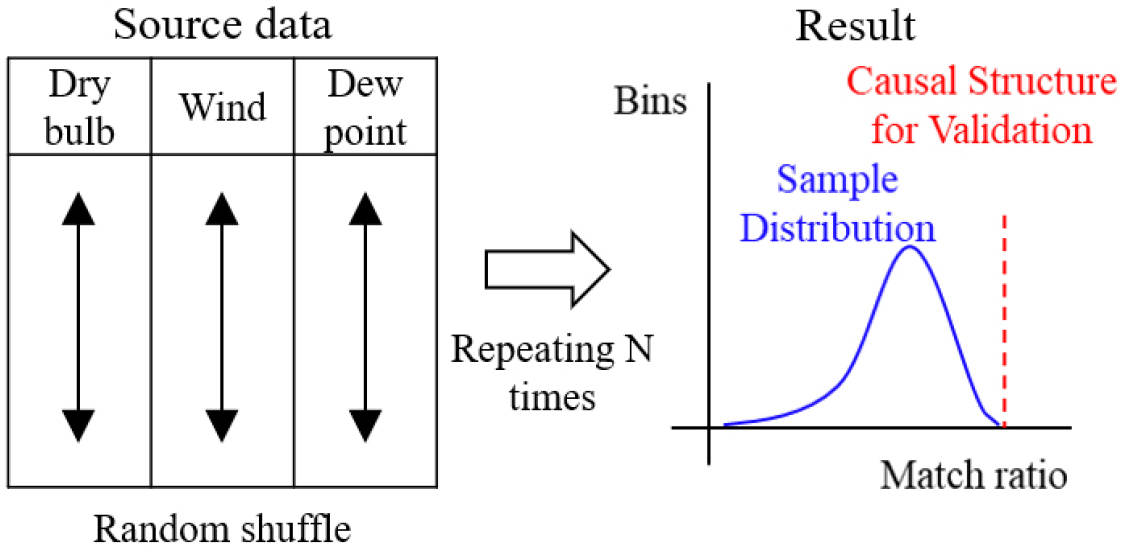
반복 검증은 발견된 구조의 안정성을 평가하기 위한 접근 방법으로, Figure 5와 같이 복원추출 (sampling with replacement)을 통해 데이터셋을 생성하고, 각 데이터셋에서 반복적으로 나타나는 인과 연결의 빈도를 누적하여 분석한다. 순열검증과 달리 각 변수 열의 값이 무작위로 섞이지 않으므로 특정 인과관계를 반복하여 발견 가능하다.
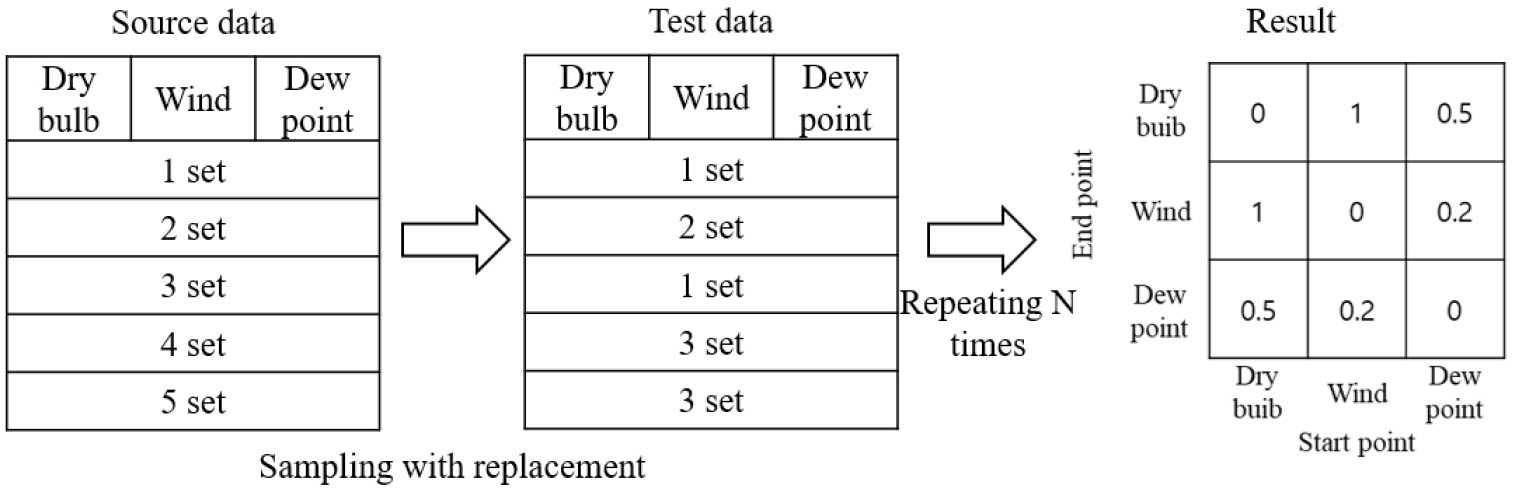
이러한 두 가지 검증 과정을 통해 연구자는 자신이 발견한 인과 구조가 우연에 의해 도출된 것인지, 혹은 데이터 전반에서 일관되게 나타나는 안정적인 관계인지를 평가할 수 있으며, 그 결과는 인과 구조의 타당성에 대한 신뢰도를 높이는 데 기여할 수 있다.
모의실험
날씨 데이터 및 임의 정답 구조 설계
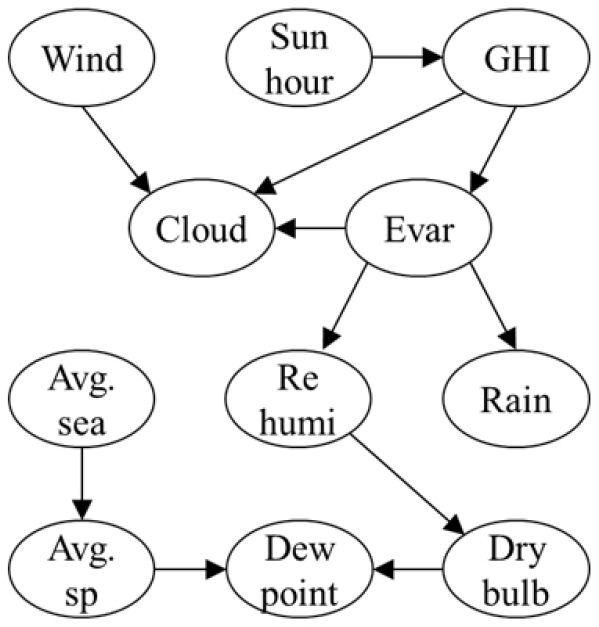
여름철 건물 에너지 사용에 영향을 미치는 기상 요인 간 인과관계를 분석하기 위하여 2024년 여름기간(7월과 8월) 동안 한국 서울에서 수집된 일일 측정값으로 인과발견용 데이터셋을 구성하였다. 총 11개의 변수가 선정되었으며, 이는 풍속(Wind), 일조시간(Sun hour), 수평면 일사량(Global horizontal irradiation, 이하 GHI), 구름량(Cloud), 증발량(Evar), 해면기압(Avg.sea), 상대습도(Re humi), 일일 강수량(Rain), 평균 증기압(Avg.sp), 이슬점 온도(Dew point), 건구 온도(Dry bulb)이다. 각 변수에서 발생한 결측치의 경우, 강수량의 결측치는 0 mm/day로 대체하였으며, 그 외 변수의 결측치는 전일과 후일의 평균값을 사용하였다. 본 연구에서는 습공기 선도에 포함되는 상대습도, 이슬점온도, 건구온도 이외의 변수들 간 인과관계에 대한 합의된 정답 구조는 존재하지 않은 상황을 가정하고, 저자의 경험적 지식을 바탕으로 11개 변수 간의 준 정답구조(Quasi-ground truth)를 설계하였다(Figure 6).
인과구조 비교 분석
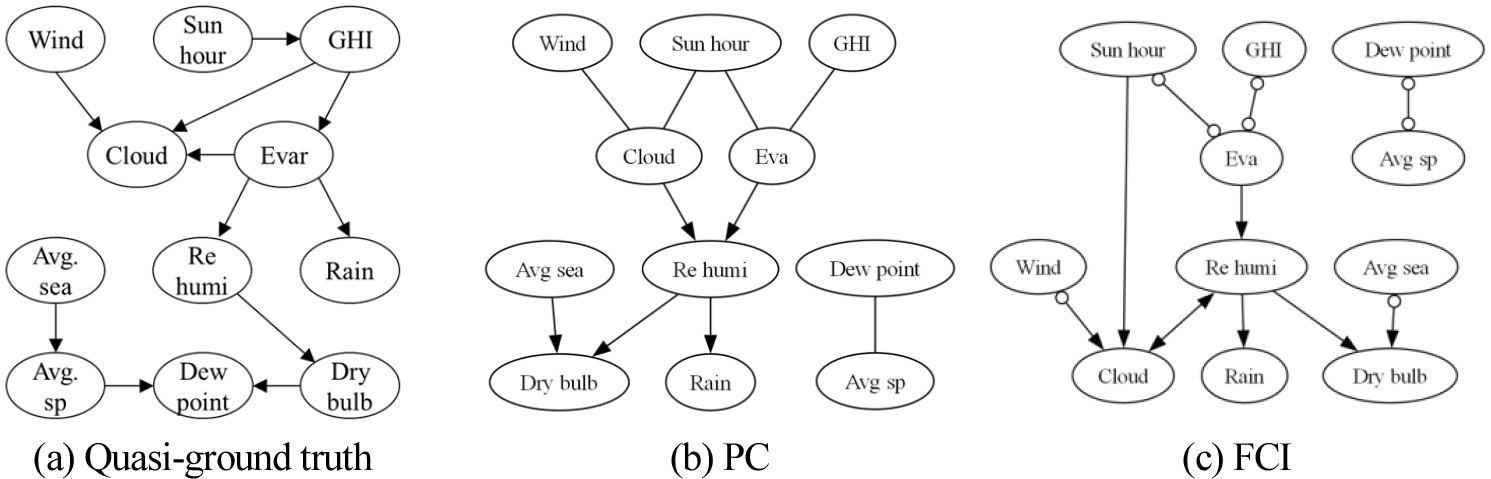
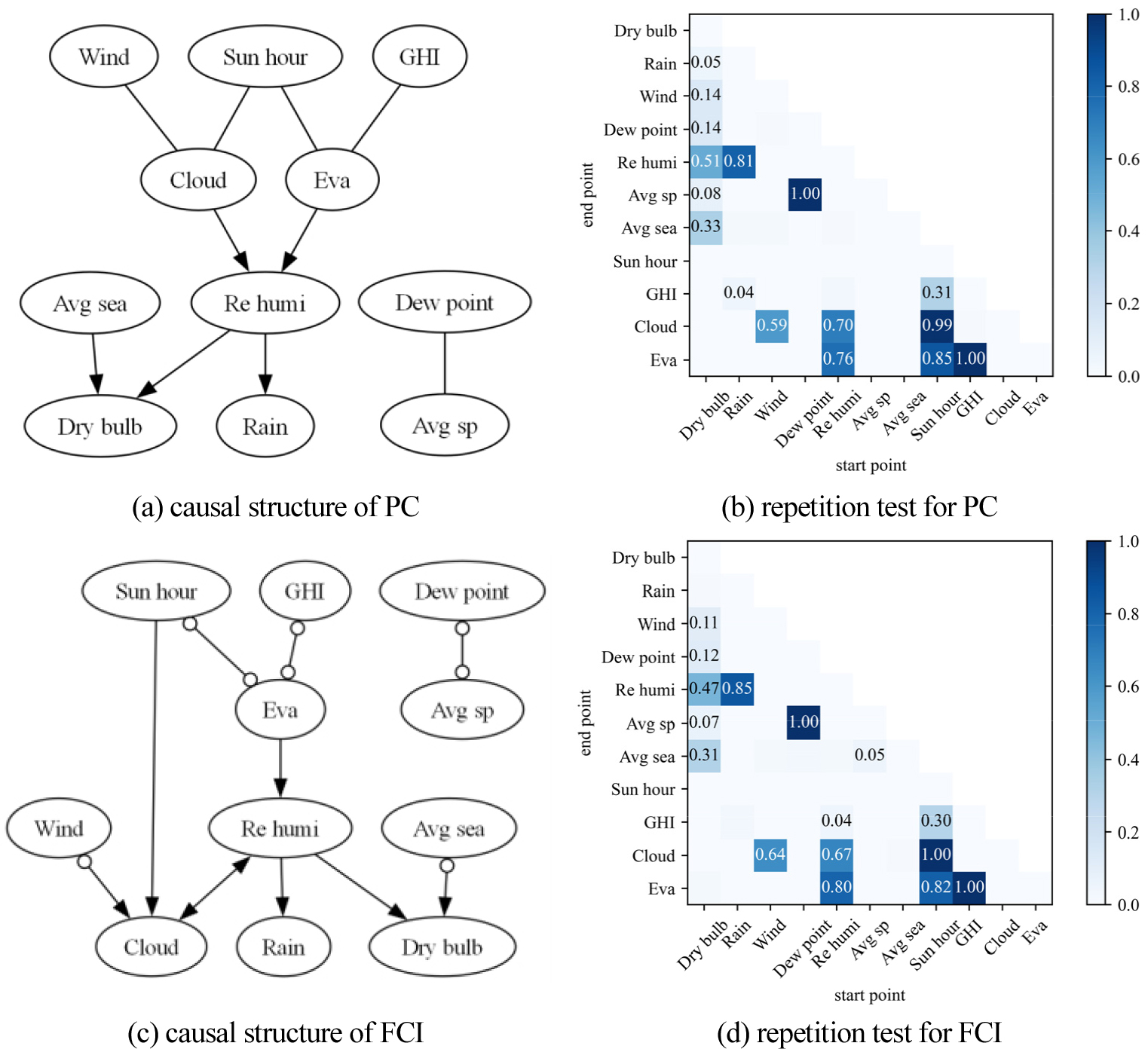
Figure 7은 저자가 설계한 준정답 구조(ground truth)와 기상 데이터셋을 대상으로 PC 및 FCI 알고리즘을 적용하여 수행한 인과발견 결과를 함께 제시한 것이다. Figure 7(a)에 나타난 저자의 예상과는 달리, 7월과 8월의 날씨 데이터에서는 이슬점 온도(Dew point)와 평균 증기압(Avg. sp)이 다른 변수들과 상호작용하지 않고 고립되어 있는 것으로 나타났다. 또한, 수평면 일사량(GHI)은 일조시간(Sun hour)과 인과적으로 연결되어 있기보다는, 독립적인 외부 요인으로 작용하는 경향을 보였다.
저자가 설정한 정답 구조에서는 증발량(Evar)이 일 강수량(Rain)에 직접적인 영향을 미친다고 가정하였으나, 실제 발견된 구조에서는 상대습도(Re humi)가 두 변수 사이의 매개변수로 작용할 수 있음을 시사하였다. 더불어, FCI 알고리즘은 구름량(Cloud)과 상대습도 사이에 관측되지 않은 교란 요인이 존재함을 암시하였으며, 이는 추가적인 분석의 필요성을 나타낸다(Figure 7(c)).
발견된 구조 검증
Figure 8은 총 200개의 순열 검증 샘플에 대해 인과발견 알고리즘을 적용하고, 그 결과를 이전 절에서 도출한 구조(Figure 7(b) 및 7(c))와 비교한 것이다. 1에 가까울수록 순열 검증 샘플에서 발견된 인과구조가 검증대상 구조와 동일하다는 의미이며, 일치율 분포가 1에 가까울수록 발견한 인과구조는 신뢰성 있는 고유 구조일 가능성이 높아진다. 검증 결과 “알고리즘이 발견한 구조가 우연히 발생한 것이다”라는 귀무가설에 대한 p-value는 두 알고리즘 모두 0.00으로, 유의수준인 0.05를 훨씬 하회하여 귀무가설을 반박하였으며, 이는 발견된 구조가 순전히 우연에 의해 도출되었을 가능성이 매우 낮음을 나타낸다.
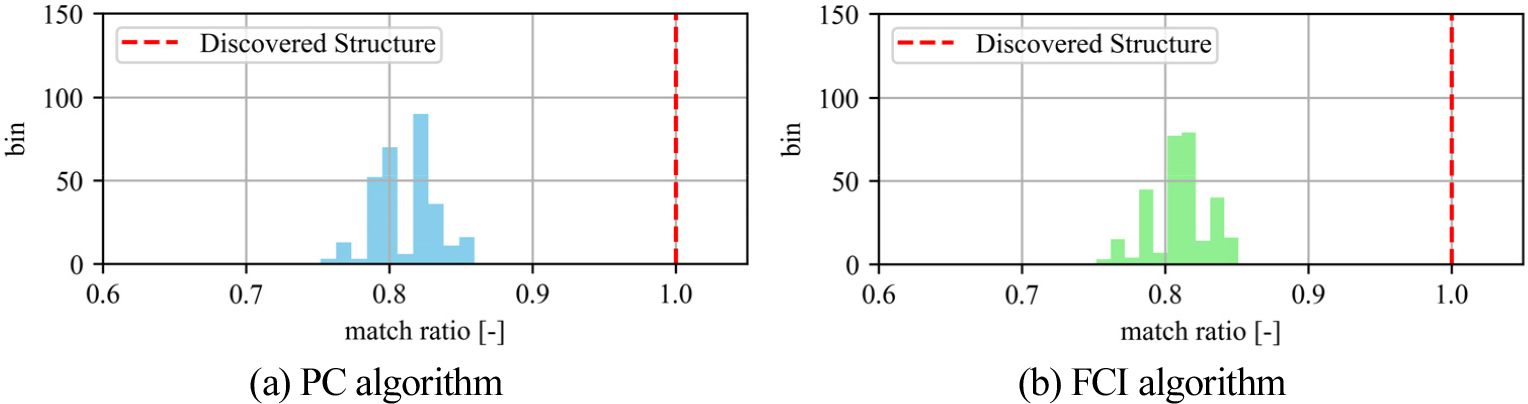
Figure 9(a), 9(c)는 Figure 7(b), 7(c)에서 발견한 구조이며, Figure 9(b), 9(d)는 반복검증을 위한 100개의 부트스트랩 샘플에 대해 인과발견 알고리즘을 적용한 뒤, 각 인과 연결이 얼마나 자주 반복적으로 나타났는지를 비율로 나타낸 것이다. Figure 9(b), 9(d)에 강조된 셀은 Figure 9(a), 9(c)에서 확인 가능한 연결관계를 나타내며, 이를 통해 원본 구조에서 발견한 연관성이 얼마나 안정적으로 발견되는지 확인 가능하다. 일례로, PC 알고리즘의 경우 원본 구조에서 발견되는 외기온(Dry bulb), 해면기압(Avg sea) 및 상대습도(Re humi)관계는 40% 이상 반복되는 관계임을 나타낸다(Figure 9(a), 9(b)). 결과적으로, 두 알고리즘 모두 40% 이상 반복되어 나타난 관계들에 대해 일관되게 구조를 도출하는 경향을 보였으며, 특히 이슬점 온도(Dew point)-평균 증기량(Avg sp), 일조시간(Sun hour)-구름량(Cloud), 수평면 일사량(GHI)-증발량(Evar) 간의 강한 인과관계는 거의 모든 재샘플링된 데이터셋에서 지속적으로 확인되는 강한 연관성을 가진 관계임을 확인하였다. 그러나 정확한 인과방향을 의미하는 화살표를 가진 구조(해면기압→외기온, 구름량→상대습도, 증발량→상대습도, 상대습도→일일 강수량, 상대습도→외기온)의 경우 반복도는 약40~80%를 나타내고, 방향을 정하기 힘든 인과구조(풍속-구름량, 일조시간-구름량, 일조시간-증발량, 수평면 일사량-증발량, 이슬점 온도-평균증기압)의 반복도는 약 50~100%의 반복도를 나타내어 구조 반복도와 인과방향의 확실함은 비례하지 않음을 확인하였다.
결 론
본 연구에서는 기상 데이터가 냉방에너지에 미치는 인과적 영향을 분석하기에 앞서 한국의 여름철 기상 데이터를 대상으로 두 가지 인과발견 알고리즘을 적용하고 비교하였으며, 발견된 인과관계를 평가하기 위한 두 가지 검증 방법을 제안하였다. 그 결과, 경험적으로 가정된 인과 지식과 데이터 기반으로 도출된 인과 지식 사이에 괴리가 존재할 수 있음을 확인하였으며, 특히 FCI 알고리즘을 통해 변수간 영향을 미치는 숨겨진 요인의 존재에 대한 통찰을 얻을 수 있음을 확인하였다. 실제 데이터는 연관된 모든 변수를 측정할 수 없으며, 거시적(macro)인 변수는 숨겨진 변수의 영향을 이미 내포하고 있을 수 있으므로, 복수의 알고리즘을 사용한 탐색을 통해 인과관계 고찰할 필요가 있다. 또한 발견된 구조의 신뢰성을 평가할 수 있는 통계적 근거를 제시하여, 비교 대상인 정답 구조가 없는 경우에도 신뢰성을 평가할 수 있음을 보였다.
다만 본 연구의 데이터의 범위는 서울 지역의 여름철(7~8월) 데이터로 한정되어 있으며, 건물 에너지 사용량이 포함되어있지 않아 기상 요인과 건물 에너지에 미치는 인과 영향력에 대한 분석이 필요하다. 또한 PC 및 FCI 알고리즘과 같은 제약 기반 방법은 선형적이고 가우시안 분포를 가진 변수 간 인과관계를 발견하는것에는 적합하나, 비선형, 비가우시안 분포를 가지는 데이터에 있어서는 독립성 검정 약화로 인한 인과관계 왜곡이 발생할 수 있으므로 데이터 전처리나 추가적인 알고리즘 접근 방법이 필요할 것으로 판단된다. 향후 연구에서는 간절기 및 겨울철과 같은 다양한 계절이나 서울 이외 지역에 대하여 인과관계를 분석하고 비교하는 프로세스를 제안하거나, 데이터셋을 건물 요인과 에너지 소비 항목까지 확장하여 기상 및 건물 요인이 건물 에너지에 미치는 인과구조를 분석할 예정이며, 이외에도 발견한 구조를 보완하는 방법에 대해 탐색할 예정이다.
